
If you read one thing this week for model optimization techniques, it should be this thesis:


Articles

Google wrote a blog post on their auto-generated summary for google docs in here. They use Pegasus architecture that we mentioned before in the newsletter by extending the idea through Gap Sentence Prediction(GSP). By doing so, they create a self-supervised learning objective GSP and they fulfill this task and this task is actually what summary of the doc is!
More in details:
The Pegasus work took this idea one step further, by introducing a pre-training objective customized to abstractive summarization. In Pegasus pre-training, also called Gap Sentence Prediction (GSP), full sentences from unlabeled news articles and web documents are masked from the input and the model is required to reconstruct them, conditioned on the remaining unmasked sentences. In particular, GSP attempts to mask sentences that are considered essential to the document through different heuristics. The intuition is to make the pre-training as close as possible to the summarization task. Pegasus achieved state-of-the-art results on a varied set of summarization datasets. However, a number of challenges remained to apply this research advancement into a product.

ML@CMU wrote about generalization errors in deep learning flows in the following blog post.
Stochastic gradient descent (SGD) is perhaps the most popular optimization algorithm for deep neural networks. Due to the non-convex nature of the deep neural network’s optimization landscape, different runs of SGD will find different solutions. As a result, if the solutions are not perfect, they will disagree with each other on some of the unseen data. This disagreement can be harnessed to estimate generalization error without labels:
Given a model, run SGD with the same hyperparameters but different random seeds on the training data to get two different solutions.
Measure how often the networks’ predictions disagree on a new unlabeled test dataset.
Tensorflow has a number of good articles around how to write recommender systems in the following page.
Multitask tutorial has a structured recommender system tutorial.
Deep-Cross Networks has also another good tutorial.
Listwise-ranking talks about how to adopt list-wise ranking loss to build recommender systems.
Xavier Amatriain wrote about Transformers(what they are) and a number of different modified versions in the blog post.

Salesforce wrote about explainability and diversity controls that they have built for their recommendation systems for different apps/vendors in the following blog post.
Libraries
Did It spill is a small, nice utility library that checks if there is a spill between training and test dataset. The library computes hashes of your data to determine if you have samples spilled over from your train set to test set, supports for PyTorch.
Alpa is a library
Introductory talk is here.
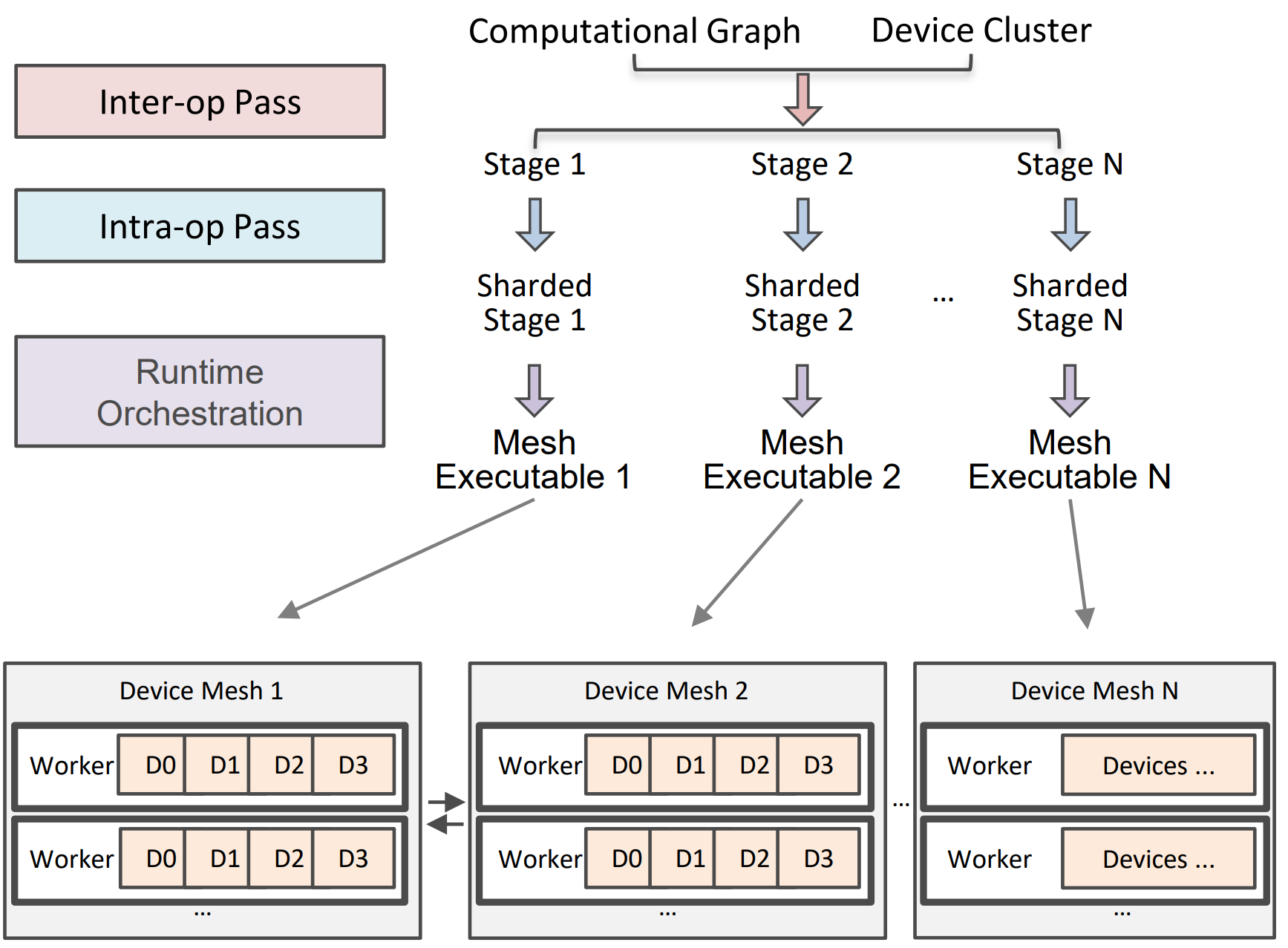
Its architecture and more details are in the documentation, the paper goes into detail much more.
Books
Foundations of Data Science covers mathematical foundations of traditional machine learning algorithms. It is written by John Hopkins researchers and give a good amount of detailed explanations for a variety of topics in data science and machine learning.