Foundational Models and Compute Trends
Software^2, Efficient methods from Google for mixed integer programming

Articles
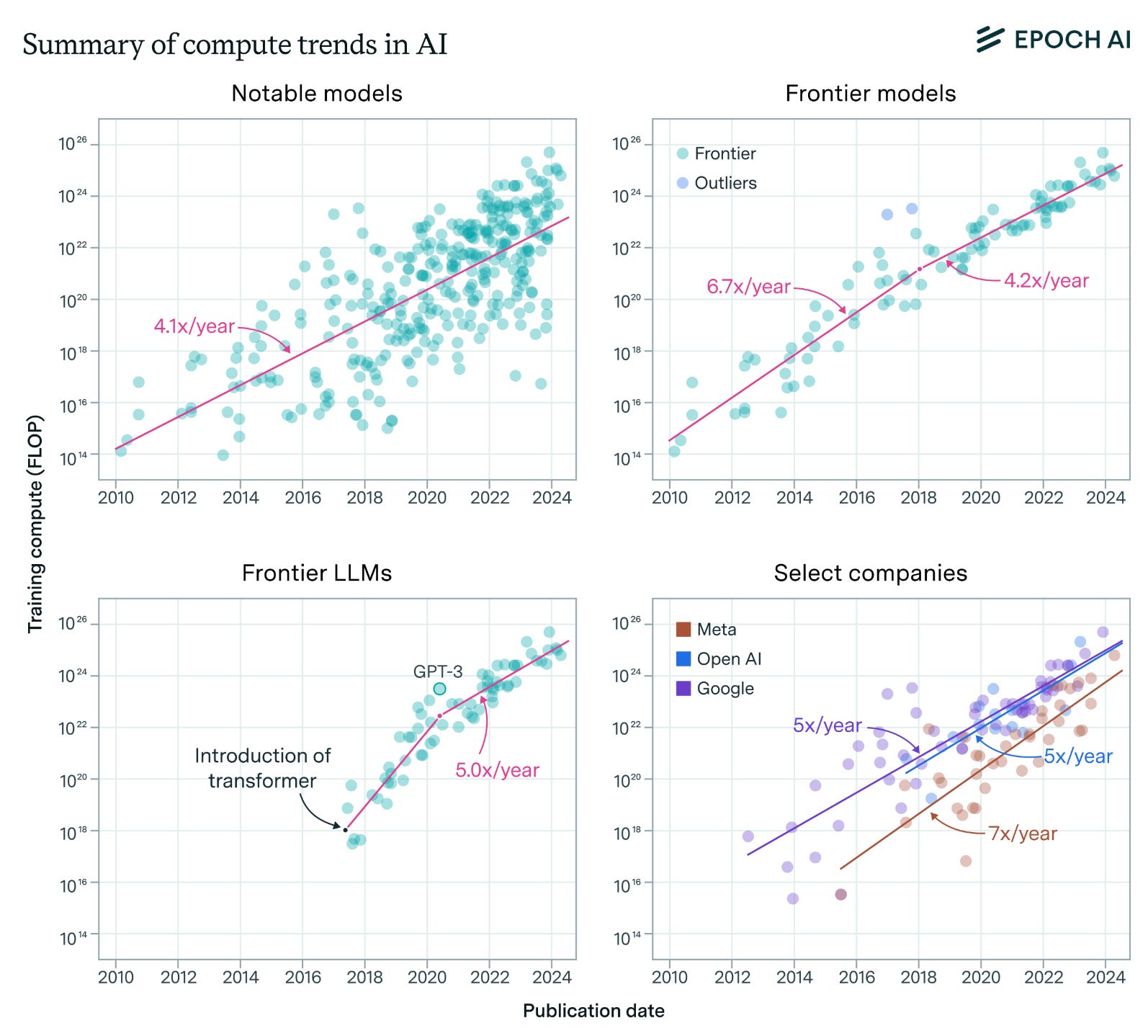
Epoch AI wrote a very comprehensive survey like blog post on the compute trends across all of the foundational models and key trends in compute.
The compute used to train recent AI models has grown at a staggering rate of 4-5x per year from 2010 to May 2024. This rapid growth is observed across frontier models, recent large language models, and models from leading companies.
The compute growth for models at the cutting edge (top 10 in training compute when released), referred to as "frontier models", has slowed down recently but now aligns with the overall 4-5x per year trend across all models.
The amount of compute used for training the largest models is doubling approximately every 7 months.
Costs for training the largest models are doubling roughly every 10 months, with current frontier models costing tens of millions of dollars just for the final training run.
The full cost of training frontier models today, including earlier runs and experiments, could be around $100 million.
As costs continue rising, training frontier models could reach hundreds of millions or even billions of dollars.
The authors recommend using the 4-5x per year figure as a baseline for expected future compute growth, while considering potential bottlenecks or accelerating factors.
Some projection from the post:
By the late 2020s or early 2030s, the compute used to train frontier AI models could be approximately 1,000 times that used for GPT-4.
Accounting for algorithmic progress, the effective compute could be around one million times that used for GPT-4.
This level of growth appears possible within anticipated cost limits for large tech companies and without fundamental hardware breakthroughs.
Rising training costs may drive an oligopoly at the frontier, but capabilities are likely to proliferate rapidly as costs decline for any given model capability.
Export controls denying access to latest hardware can create a growing capability gap, with a 10x cost penalty by 2027 for using older chips.
However, proliferation is only delayed by 2-3 years for any capability level due to algorithmic progress reducing compute needs over time.
The exponential growth in training compute is a key driver behind the rapid progress in AI capabilities. The authors argue that massive amounts of compute will likely be an essential input for developing the most capable AI systems over the next 10-15 years. While rising costs may consolidate frontier AI development, the authors project that capabilities will still proliferate relatively rapidly due to algorithmic improvements reducing compute requirements over time.
The code is available in here for the analysis that they have run, and dataset is available in here. This also has a walkthrough of all of the visualizations in the post as well.

Gradient wrote a post on "Software^2" as a paradigm shift in the development of AI systems, building upon the limitations of the current deep learning (Software 2.0) approach. While deep learning has made significant progress, it relies on manually provided training data for each new task, limiting its ability to generalize.
The main argument of the post is that the ability to actively acquire relevant data for training at the right time is as important as the model itself to be able to build a very strong model. This process of exploration allows for efficient learning and progression, akin to the concept of "learning to walk before you run." However, the main argument goes that this aspect of exploration is largely missing in the current discourse around training more general AI models.
Large-scale model training continues to exploit the benefits of ever-larger datasets, researchers have projected that the rate of growth of training datasets may soon outstrip the organic growth of high-quality data on the web, potentially as soon as 2025. This limitation highlights the need for a new approach to data acquisition and model training. The core idea of "Software2" is that AI systems should be able to improve themselves by searching for and generating their own training data. This paradigm is described as a kind of "Software2," inheriting the benefits of Software 2.0 (deep learning) while addressing its data-bound weaknesses. Unlike deep learning, which requires programmers to manually provide training data for each new task, Software2 recasts data as software that searches and models the world to produce its own, potentially unlimited, training tasks and data.
The post suggests that open-ended exploration processes, where AI systems actively seek out and generate their own training data, can serve as a key component in driving progress toward more generally intelligent models. These exploration processes allow for continuous learning and adaptation, enabling AI systems to tackle a wider range of tasks and domains.

The post also mentions that the Software^2 paradigm could have far-reaching implications for the design of future software systems, potentially being as influential as the transition to Software 2.0 (deep learning) itself. The ability of AI systems to generate their own training data could lead to more efficient and effective learning, enabling them to tackle a broader range of tasks and domains without the need for extensive manual data curation and labeling.
Google researchers developed an optimization system and wrote a blog post on titled “Heuristics on the high seas: Mathematical optimization for cargo ships” to improve the routing and scheduling of cargo ships to reduce fuel consumption and emissions.
The key technical components that they have developed to solve this problem:
Mixed-Integer Programming (MIP) Model
They formulated LSNDSP as a large mixed-integer programming model, with binary variables for cargo-ship assignments and ship transits between ports, and continuous variables for ship speeds. This integrated the network design, scheduling, and container routing components into one holistic optimization model.
Column Generation Technique and Double Column Generation
To handle the massive scale, they employed a column generation technique where only a subset of variables (columns) are considered initially. New columns representing promising routes/schedules are dynamically generated and added to better approximate the full problem. This decomposition approach reduces the computational complexity.
They treated network design/scheduling and container routing as two coupled subproblems. A novel "double column generation" method was developed, where column generation was applied to both subproblems simultaneously, using intermediate results from one to guide the other. This coupled approach is more effective than solving the subproblems sequentially.
Shortest Path through Local Search
To generate new columns (routes/schedules) for the column generation process, they applied efficient shortest path algorithms tailored for the shipping constraints.This provided a smart way to explore promising new routes instead of enumerating all possibilities.
Since the full MIP model was still intractable for the largest instances, they developed local search metaheuristics like large neighborhood search and variable neighborhood search.These explored neighborhoods around existing solutions in parallel across multiple machines to find improvements efficiently.
If you are looking to build a mixed integer optimization solution on a very large scale, I recommend taking a look at this post in terms of efficiency techniques that Google has developed.
Libraries

Koheesio, named after the Finnish word for cohesion, is a robust Python framework for building efficient data pipelines. It promotes modularity and collaboration, enabling the creation of complex pipelines from simple, reusable components.
The framework is versatile, aiming to support multiple implementations and working seamlessly with various data processing libraries or frameworks. This ensures that Koheesio can handle any data processing task, regardless of the underlying technology or data scale.
Koheesio uses Pydantic for strong typing, data validation, and settings management, ensuring a high level of type safety and structured configurations within pipeline components.
Koheesio's goal is to ensure predictable pipeline execution through a solid foundation of well-tested code and a rich set of features, making it an excellent choice for developers and organizations seeking to build robust and adaptable Data Pipelines.
fklearn uses functional programming principles to make it easier to solve real problems with Machine Learning.
The name is a reference to the widely known scikit-learn library.
fklearn Principles
Validation should reflect real-life situations.
Production models should match validated models.
Models should be production-ready with few extra steps.
Reproducibility and in-depth analysis of model results should be easy to achieve.


MLRun is an open MLOps platform for quickly building and managing continuous ML applications across their lifecycle. MLRun integrates into your development and CI/CD environment and automates the delivery of production data, ML pipelines, and online applications, significantly reducing engineering efforts, time to production, and computation resources. With MLRun, you can choose any IDE on your local machine or on the cloud. MLRun breaks the silos between data, ML, software, and DevOps/MLOps teams, enabling collaboration and fast continuous improvements.
Nuclio is a high-performance "serverless" framework focused on data, I/O, and compute intensive workloads. It is well integrated with popular data science tools, such as Jupyter and Kubeflow; supports a variety of data and streaming sources; and supports execution over CPUs and GPUs. The Nuclio project began in 2017 and is constantly and rapidly evolving; many start-ups and enterprises are now using Nuclio in production.
You can use Nuclio as a standalone Docker container or on top of an existing Kubernetes cluster; see the deployment instructions in the Nuclio documentation. You can also use Nuclio through a fully managed application service (in the cloud or on-prem) in the Iguazio Data Science Platform, which you can try for free.

Vizro allows rapidly self-serve the assembly of customized dashboards in minutes - without the need for advanced coding or design experience - to create flexible and scalable, Python-enabled data visualization applications.