Exphormer(Graph Neural Networks)
Mixed-input matrix multiplication performance optimizations, JAX Libraries

Articles

Google wrote an article on the new graph based transformer architecture called Exphormer and how they scaled this model for their datasets. Graph transformers are a powerful architecture for machine learning on graph-structured data like molecules, social networks, and knowledge graphs. Existing graph transformers struggle with scaling to large graphs due to memory limitations and computational complexity of fully-connected attention mechanisms.
The key challenge addressed by Exphormer is overcoming the memory bottleneck arising from the dense attention matrices in fully-connected graph transformers. This limits scalability and restricts applications to smaller graphs.

And their approach is:
Expander Graphs: Exphormer uses "expander graphs" as a sparse but informative representation of the original graph. These graphs offer good connectivity while maintaining sparsity, reducing memory consumption for attention computations.
Intermediate Nodes: To compensate for the information loss from reduced edge density, Exphormer introduces intermediate nodes within the expander graph. These nodes aggregate and redistribute information, capturing long-range dependencies efficiently.
Hybrid Attention: Exphormer combines three types of attention mechanisms:
Edge Attention: Captures local relationships between directly connected nodes.
Intermediate Attention: Aggregates information through intermediate nodes.
Global Attention: Allows for long-range information exchange across the entire graph.
Through these approaches, Exphormer can scale well with the large and increased datasets overall.

Google wrote an excellent ML efficiency post on how they optimized mixed-input matrix multiplication for LLMs. As LLMs:
are memory-intensive and require specialized hardware accelerators to deliver tens of exaflops of computing power.
use memory and compute are consumed by weights in matrix multiplication operations.
can use narrower data types like 8-bit integers can reduce memory consumption by 4x compared to single-precision.
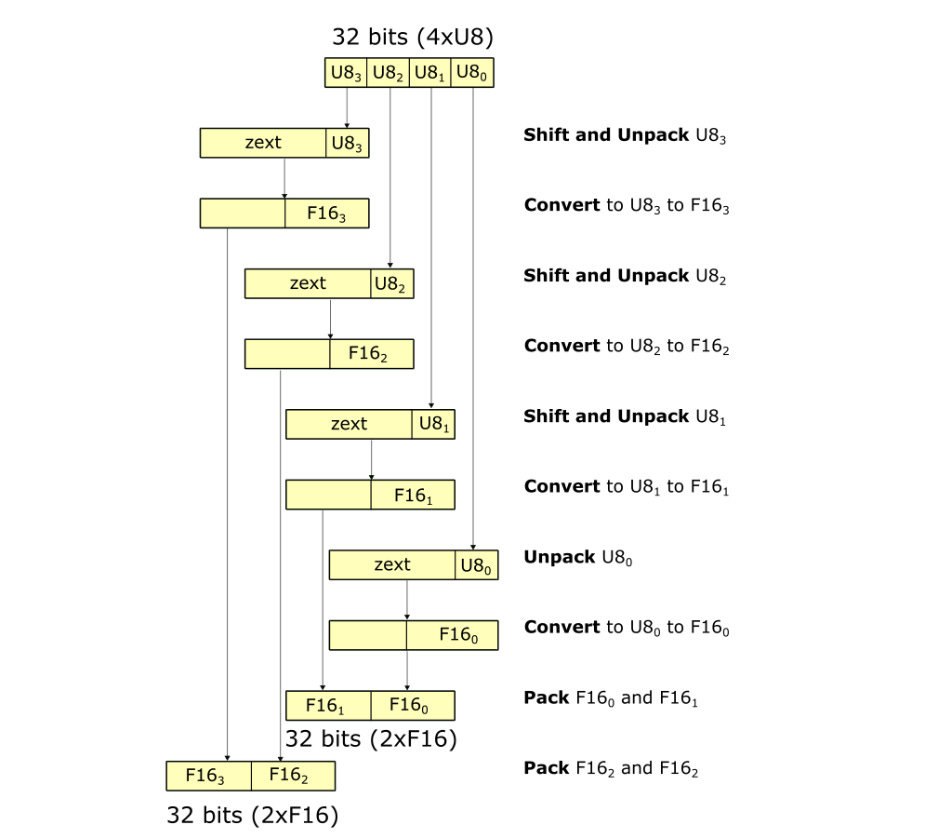
In order to optimize the computation for LLMs, they talk about how to optimize mixed-input matrix multiplication which requires transformations to map to HW operations due to that GPUs only support a fixed set of data structure.
They address data type conversion and layout conformance to map mixed-input matrix multiplication efficiently onto hardware-supported data types and layouts.

There are two innovations that they have made for this optimization:
FastNumericArrayConvertor: This technique operates on 4xU8 in 32-bit registers without unpacking individual 1xU8 values. It also uses less expensive arithmetic operations to reduce the number of instructions and increase the speed of the conversion.
FragmentShuffler: This technique handles layout conformance by shuffling data in a way that allows the use of wider bitwidth load operation, increasing shared memory bandwidth utilization and reducing the total number of operations.
Note that their post focuses on mapping mixed-input matrix multiplication onto NVIDIA Ampere architecture.

Netflix has written an article on how they detect speech and music in the
videos and what type of technologies that they use in order to do this detection.
Speech and Music Activity Detection(SMAD) can be broadly defined as a task to automatically separate speech and music segments within an audio file. This is beneficial for tasks like content segmentation, audio description generation, and personalized sound mixing. SMAD traditionally relies on hand-crafted features and statistical models, but Netflix in this post how they leverage deep learning, particularly convolutional neural networks (CNNs), for superior performance and generalizability. A classic story of tradition machine learning method with hand-crafted features are replaced by a deep learning method with raw features.
Problem to Solve:
Conventional SMAD systems struggle with:
Limited accuracy: Difficulty in distinguishing complex audio mixtures with overlapping speech and music.
Generalizability: Inability to adapt to diverse audio content beyond the training data.
Scalability: High computational cost for real-time processing in large-scale video production pipelines.
Netflix’s Approach To Address this is a CNN(Convolutional Neural Network) to solve them all:
Deep Learning Architecture: The system uses a cascade of CNNs:
First-stage CNN: Extracts low-level features like spectral energies and temporal patterns.
Second-stage CNN: Leverages learned features to classify each audio frame as speech, music, or silence.
Data Augmentation: Artificially expands the training dataset with noise, reverberation, and other variations to improve generalizability.
Efficient Inference: Implements optimizations like model quantization and pruning to enable real-time processing on diverse hardware platforms.
The dataset that they used for this post as well as the paper is also available in here.
Libraries

AutoRound is an advanced weight-only quantization algorithm, based on SignRound. It's tailored for a wide range of models and consistently delivers noticeable improvements, often significantly outperforming SignRound with the cost of more tuning time for quantization.
Haliax is a JAX library for building neural networks with named tensors, in the tradition of Alexander Rush's Tensor Considered Harmful. Named tensors improve the legibility and compositionality of tensor programs by using named axes instead of positional indices as typically used in NumPy, PyTorch, etc.
Despite the focus on legibility, Haliax is also fast, typically about as fast as "pure" JAX code. Haliax is also built to be scalable: it can support Fully-Sharded Data Parallelism (FSDP) and Tensor Parallelism with just a few lines of code. Haliax powers Levanter, our companion library for training large language models and other foundation models, with scale proven up to 20B parameters and up to a TPU v3-256 pod slice.
Equinox is your one-stop JAX library, for everything you need that isn't already in core JAX:
neural networks (or more generally any model), with easy-to-use PyTorch-like syntax;
filtered APIs for transformations;
useful PyTree manipulation routines;
advanced features like runtime errors;
and best of all, Equinox isn't a framework: everything you write in Equinox is compatible with anything else in JAX or the ecosystem.
Levanter is a framework for training large language models (LLMs) and other foundation models that strives for legibility, scalability, and reproducibility:
Legible: Levanter uses our named tensor library Haliax to write easy-to-follow, composable deep learning code, while still being high performance.
Scalable: Levanter scales to large models, and to be able to train on a variety of hardware, including GPUs and TPUs.
Reproducible: Levanter is bitwise deterministic, meaning that the same configuration will always produce the same results, even in the face of preemption and resumption.

TTS is a library for advanced Text-to-Speech generation.
🚀 Pretrained models in +1100 languages.
🛠️ Tools for training new models and fine-tuning existing models in any language.
📚 Utilities for dataset analysis and curation.

RecBole is developed based on Python and PyTorch for reproducing and developing recommendation algorithms in a unified, comprehensive and efficient framework for research purpose. Our library includes 91 recommendation algorithms, covering four major categories:
General Recommendation
Sequential Recommendation
Context-aware Recommendation
Knowledge-based Recommendation


The TV Speech and Music (TVSM) dataset contains speech and music activity labels across a variety of TV shows and their corresponding audio features extracted from professionally-produced high-quality audio. The dataset aims to facilitate research on speech and music detection tasks.