Emergent Capabilities in Large Language Models
Tricks to speed up Transformers Training, Federated Learning and Privacy

Articles
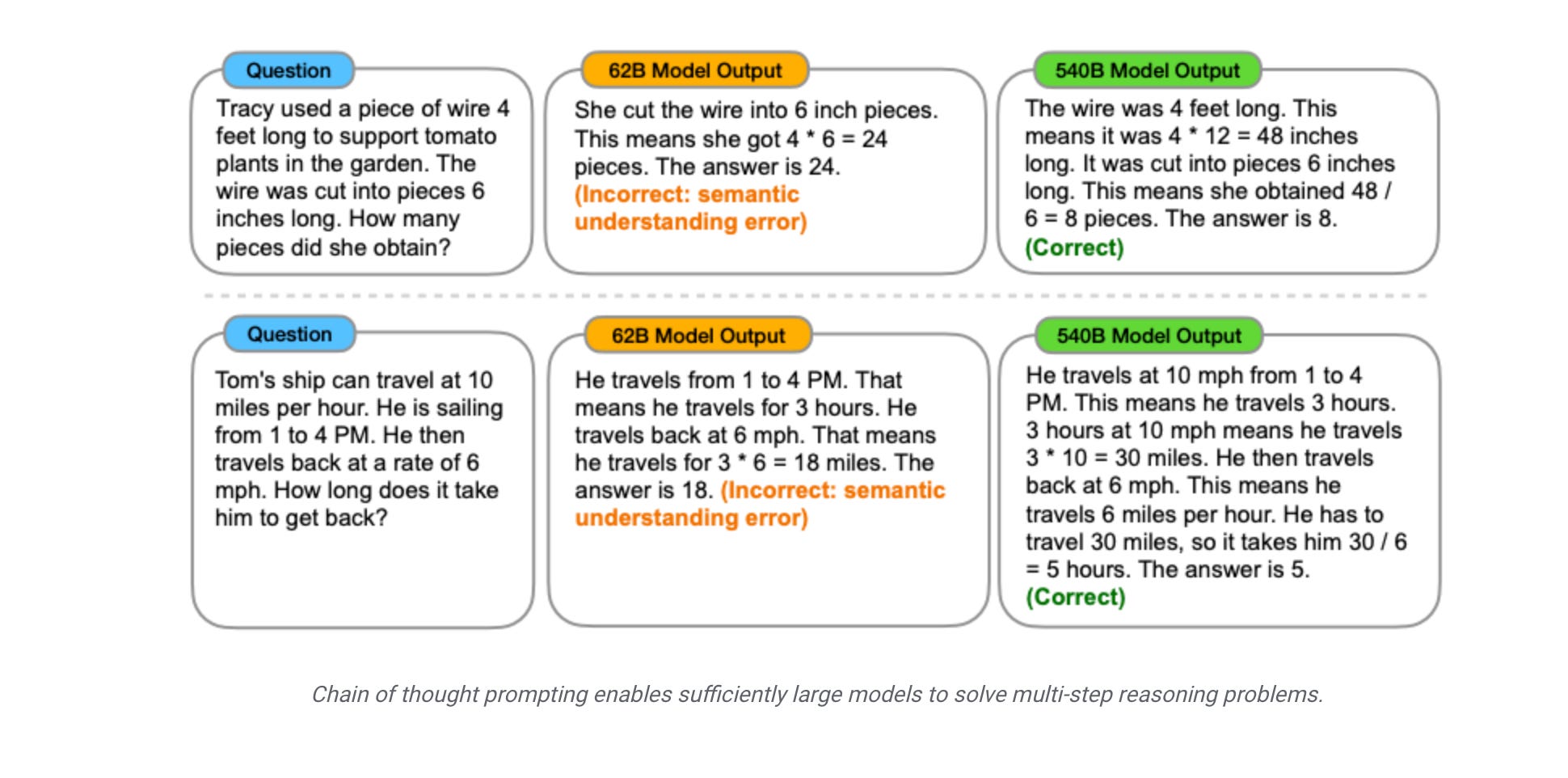
GPT-3 paper showed that the ability of language models to perform multi-digit addition has a flat scaling curve (approximately random performance) for models from 100M to 13B parameters, at which point the performance jumped substantially. Given the growing use of language models in NLP research and applications, it is important to better understand abilities such as these that can arise unexpectedly. Emergent abilities of Large Language Models paper and blog post talks about some of these emergent capabilities where emergent capabilities as abilities that are not present in small models but are present in larger models. This study of emergence is done by analyzing the performance of language models as a function of language model scale, as measured by total floating point operations (FLOPs), or how much compute was used to train the language model. However, we also explore emergence as a function of other variables, such as dataset size or number of model parameters (see the paper for full details). Defining emergent capability and comparing that against FLOPs demonstrate the return on investment well of having a larger model for a given emergent capability such as emergent prompting. It also allows to observe these capabilities as model becomes larger and larger if these properties cannot be observed in the smaller model sizes.
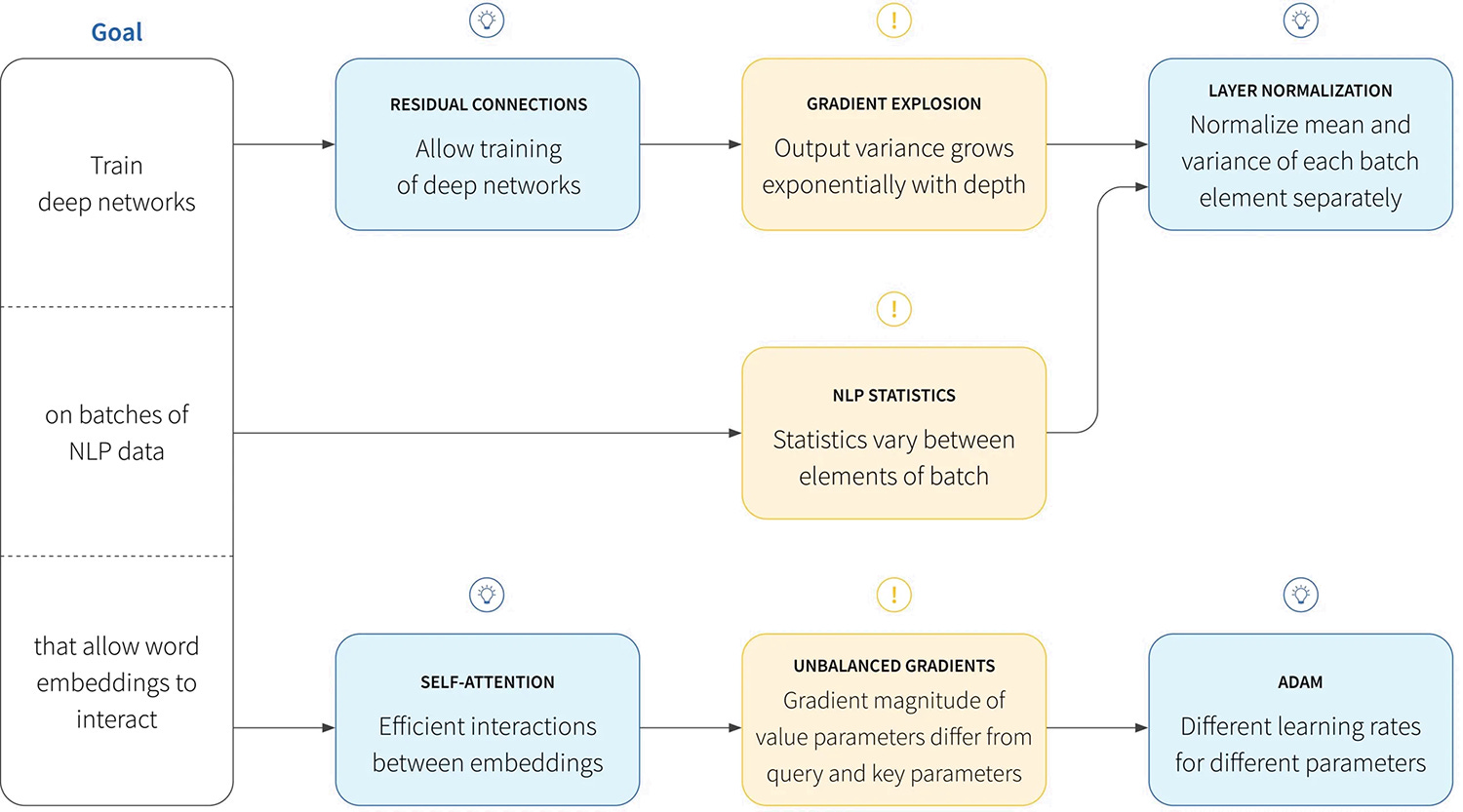
Transformers is a flexible architecture that powers most of the recent modeling innovations, but they are not very easy to train and it takes a lot of compute and memory to be able to train them well. This blog post that explains various tricks to make the training faster and allow you to train transformers on a much higher model accuracy.

Google has a post on Federated Learning and how it protects Privacy. Federated learning is a general framework that leverages data minimization tactics to enable multiple entities to collaborate in solving a machine learning problem. Each entity keeps their raw data local, and improves a global model with focused updates intended for immediate aggregation. A good first step towards limiting data exposure when combining user models is to do so without ever storing the individual models — only the aggregate. Secure aggregation and secure enclaves can provide even stronger guarantees, combining many local models into an aggregate without revealing the contribution of any user to the server. Carefully bounding the impact of any possible user contribution and adding random noise to our system can help prevent this, making our training procedure differentially private. When using differential privacy in federated learning, the overall accuracy of the global model may degrade, but the outcome should remain roughly the same when toggling inclusion of the outlier (or any other user) in the training process.
Libraries
Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. But using these LLMs in isolation is often not enough to create a truly powerful app - the real power comes when you are able to combine them with other sources of computation or knowledge.
Langchain is aimed at assisting in the development of those types of applications.
OpenAI finally published an cookbook for how you can interact with ChatGPT.

Of all the inputs to a large language model, by far the most influential is the text prompt.
This model can be prompted to produce output in a few ways:
Instruction: Tell the model what you want
Completion: Induce the model to complete the beginning of what you want
Demonstration: Show the model what you want, with either:
A few examples in the prompt
Many hundreds or thousands of examples in a fine-tuning training dataset
OpenAI has a number of nice notebooks on how to use APIs as well such as Question Anwering.
When geospatial raster data is concerned in a machine learning pipeline, it is often required to extract meaningful features, such as vegetation indices (e.g., NDVI, EVI, NDRE, etc.) or textures. Raster4ML provides easy-to-use functions that can automatically calculates the features with one or several lines of codes in Python. It also has the functionality of extracting statistics based on shapefile (i.e., point or polygon) from a raster data. Any type of raster data is supported regardless of satellite or UAVs.
This repo included the official implementation of the Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models.
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. AITemplate highlights include:
High performance: close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models, including ResNet, MaskRCNN, BERT, VisionTransformer, Stable Diffusion, etc.
Unified, open, and flexible. Seamless fp16 deep neural network models for NVIDIA GPU or AMD GPU. Fully open source, Lego-style easy extendable high-performance primitives for new model support. Supports a significantly more comprehensive range of fusions than existing solutions for both GPU platforms.
GLM-130B is an open bilingual (English & Chinese) bidirectional dense model with 130 billion parameters, pre-trained using the algorithm of General Language Model (GLM). It is designed to support inference tasks with the 130B parameters on a single A100 (40G * 8) or V100 (32G * 8) server. With INT4 quantization, the hardware requirements can further be reduced to a single server with 4 * RTX 3090 (24G) with almost no performance degradation. As of July 3rd, 2022, GLM-130B has been trained on over 400 billion text tokens (200B each for Chinese and English) and it has the following unique features:
Bilingual: supports both English and Chinese.
Performance (EN): better than GPT-3 175B (+4.0%), OPT-175B (+5.5%), and BLOOM-176B (+13.0%) on LAMBADA and slightly better than GPT-3 175B (+0.9%) on MMLU.
Performance (CN): significantly better than ERNIE TITAN 3.0 260B on 7 zero-shot CLUE datasets (+24.26%) and 5 zero-shot FewCLUE datasets (+12.75%).
Fast Inference: supports fast inference on both SAT and FasterTransformer (up to 2.5X faster) with a single A100 server.
Reproducibility: all results (30+ tasks) can be easily reproduced with open-sourced code and model checkpoints.
Cross-Platform: supports training and inference on NVIDIA, Hygon DCU, Ascend 910, and Sunway (Will be released soon).
CodeRL is a new framework for program synthesis through holistic integration of pretrained language models and deep reinforcement learning. By utilizing unit test feedback as part of model training and inference, and integrating with an improved CodeT5 model, CodeRL achieves state-of-the-art results on competition-level programming tasks.
CodeRL has the following properties that differentiates itself from the rest of the ecosystem:
During training, we treat the code-generating LMs as an actor network, and introduce a critic network that is trained to predict the functional correctness of generated programs and provide dense feedback signals to the actor.
During inference, we introduce a new generation procedure with a critic sampling strategy that allows a model to automatically regenerate programs based on feedback from example unit tests and critic scores.
With an improved CodeT5 model, our method not only achieves new SOTA results on the challenging APPS benchmark, but also shows strong zero-shot transfer capability with new SOTA results on the simpler MBPP benchmark.
Data Tools
The power of machine learning comes from its ability to learn patterns from large amounts of data. Understanding your data is critical to building a powerful machine learning system. Facets contains two robust visualizations to aid in understanding and analyzing machine learning datasets.
Know Your Data helps researchers, engineers, product teams, and decision makers understand datasets with the goal of improving data quality, and helping mitigate fairness and bias issues.