I am covering a single article today technically with RLHF and there is a book afterwards that talks about the RLHF. However, I want to call out specifically an excellent blog post in “Below the Fold” section that talks about NVIDIA and its moat/competitive landscape well(not technical, and a bit long article, though).
For this newsletter specifically, I suggest putting some time aside as we have a ton of material!
Articles
Yuge Shi wrote an article on reinforcement learning concepts; especially ones that are used in the GenAI papers and comparison with the methods that DeepSeek has used.
It does a deep dive into two reinforcement learning algorithms used in training large language models (LLMs):
Proximal Policy Optimization (PPO)
Group Relative Policy Optimization (GRPO)
LLM Training Overview
The training of LLMs is divided into two phases:
Pre-training: The model learns next token prediction using large-scale web data.
Post-training: This phase aims to improve the model's reasoning capabilities and typically involves two stages: a. Supervised Fine-tuning (SFT): The model is fine-tuned on high-quality expert reasoning data. b. Reinforcement Learning from Human Feedback (RLHF): Uses human feedback to train a reward model, which then guides the LLM's learning via RL.
DeepSeek's Efficient Post-training Approach
The author highlights DeepSeek's innovative approach in their R1-zero model:
Skipping the SFT stage: They apply RL directly to the base model (DeepSeek V3).
Using GRPO instead of PPO: This eliminates the need for a separate critic model, reducing memory and compute overhead by about 50%.
Benefits of this approach include:
Computational efficiency
Open-ended learning through exploration
Avoiding biases from human-curated SFT data
The RLHF process is broken down into four steps:
Sample multiple responses from the model for each prompt.
Have humans rank these outputs by quality.
Train a reward model to predict human preferences/rankings.
Use RL (e.g., PPO, GRPO) to fine-tune the model to maximize the reward model's scores.
Reward Model
The reward model automates the process of ranking model outputs, reducing the need for human annotators. It is trained to predict human preferences using the following objective:L(ϕ)=−logσ(Rϕ(p,ri)−Rϕ(p,rj))L(ϕ)=−logσ(Rϕ(p,ri)−Rϕ(p,rj))Where:
RϕRϕ is the learnable reward model
pp is the prompt
riri and rjrj are responses
σσ is the sigmoid function
This objective is derived from the Bradley-Terry model, which defines the probability that a rater prefers riri over rjrj.
Proximal Policy Optimization (PPO)
PPO is a popular RL algorithm used in RLHF. It involves three main components:
Policy (πθπθ): The pre-trained or SFT'd LLM.
Reward model (RϕRϕ): A trained and frozen network that provides scalar rewards for complete responses.
Critic (VγVγ): Also known as the value function, it predicts scalar rewards for partial responses.
The PPO workflow consists of five stages:
Generate responses
Score responses
Compute advantages
Optimize policy
Update critic
PPO
States and Actions
In the context of LLMs:
State (stst): The prompt plus all previously generated tokens up to time t.
Action (atat): The token generated by the LLM at time t.
General Advantage Estimation (GAE)
GAE is used to compute the advantage, which defines how much better a specific action is compared to an average action. It balances bias and variance through multi-step Temporal Difference (TD) learning.
The GAE is computed as:
GAE=∑t=0K−1(λ)tδtAKGAE=∑t=0K−1(λ)tδt
where:
KK is the number of TD steps
λλ controls the trade-off between variance and bias
δtδt is the TD error at step t
The Critic (Value Function)
The critic is trained to anticipate the final reward given only a partial state. Its objective is:
Simplicity: GRPO is easier to implement and understand compared to PPO.
Efficiency: By eliminating the critic network, GRPO reduces memory and compute requirements.
Stability: The relative advantage computation helps stabilize training.
DeepSeek R1 Techniques
DeepSeek adopts the following approach by utilizing the some of the above approaches and not use some of them such as PPO:
Skipping SFT: Applying RL directly to the base model.
Using GRPO instead of PPO: Reducing computational requirements.
Efficient reward modeling: Using a smaller reward model and distilling it into the policy.
Prompt engineering: Carefully designing prompts to guide the model's behavior.
Curriculum learning: Gradually increasing the difficulty of tasks during training.
Multi-task training: Combining various tasks to improve general capabilities.
Efficient implementation: Optimizing code for better hardware utilization.
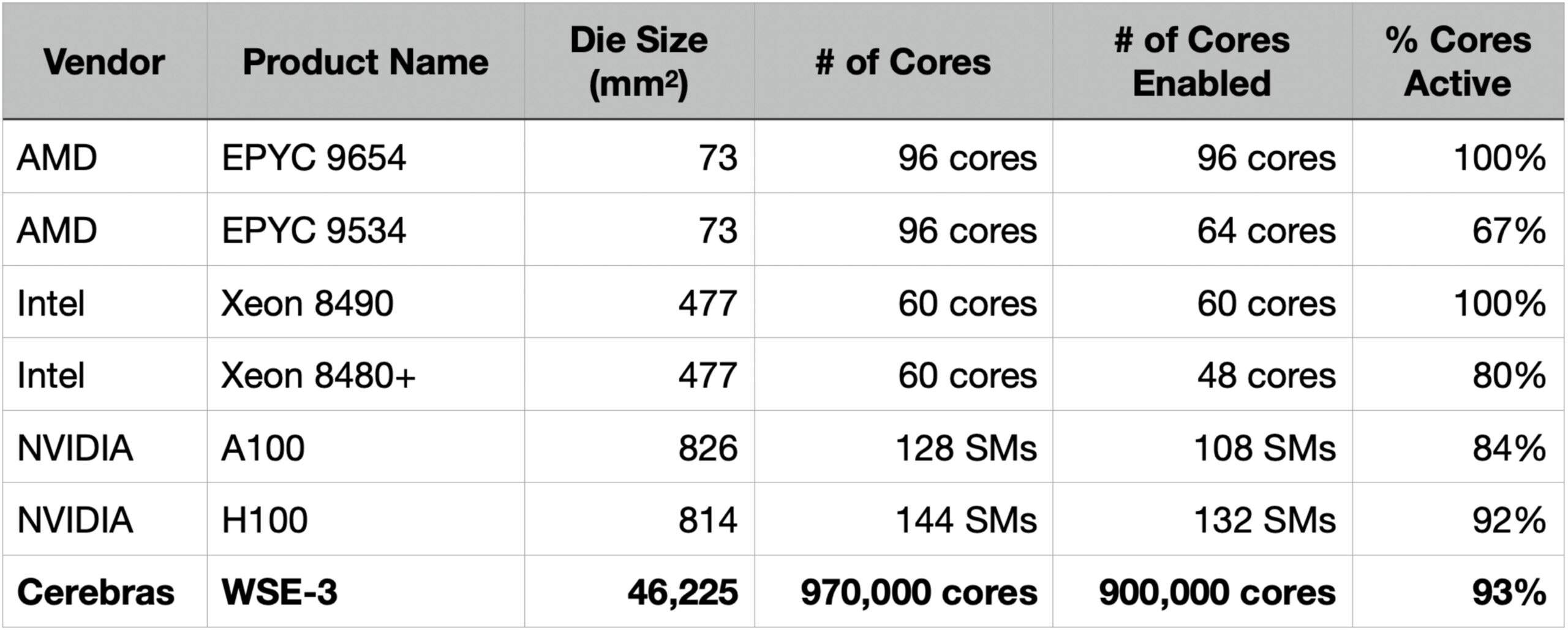
Cerebras Systems has wrote an article on semiconductor manufacturing by achieving viable yields for wafer-scale processors despite their massive size, challenging the longstanding belief that larger chips inherently suffer from lower yields. The Cerebras Wafer Scale Engine (WSE-3), which is 50x larger than conventional GPUs like Nvidia’s H100, demonstrates comparable or better yields through innovative defect tolerance strategies.
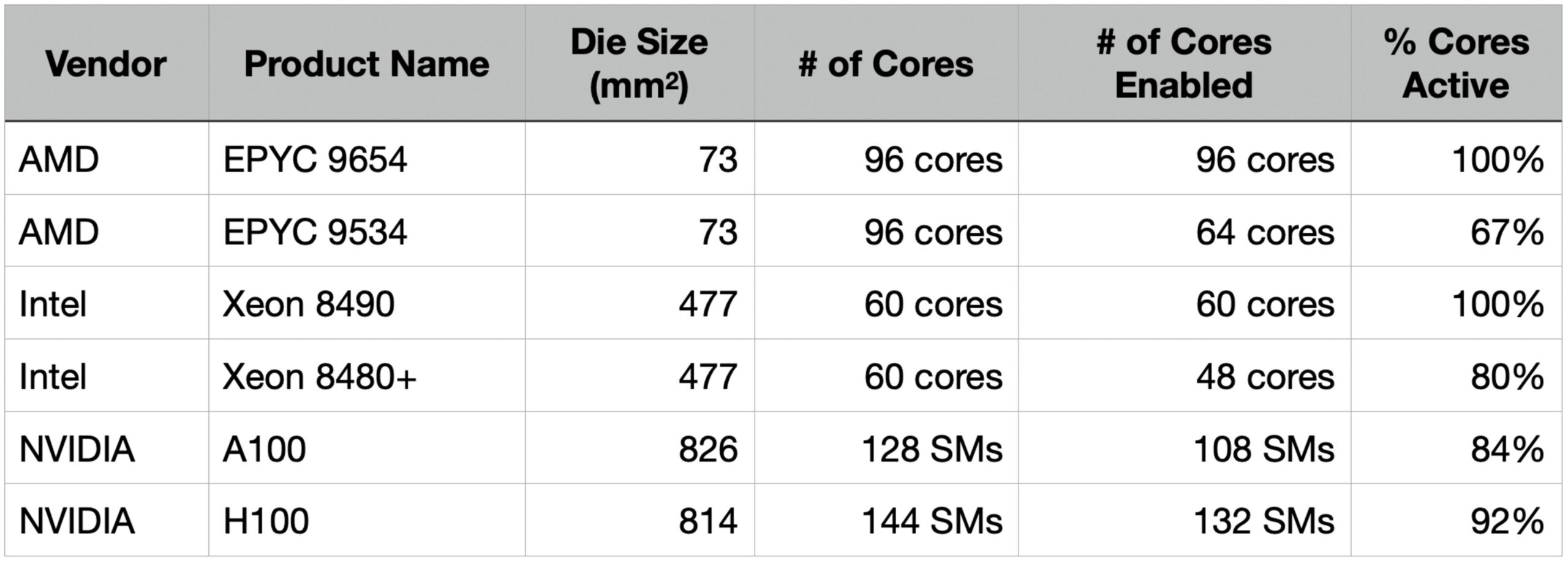
Yield in chip manufacturing depends on defect rates and the ability to tolerate defects. Larger chips historically faced lower yields due to higher probabilities of defects across their surface area. Modern processors, however, use core-level fault tolerance—disabling defective cores while keeping others operational. For example:
Nvidia H100: This 814mm² GPU contains 144 streaming multiprocessors (SMs), but only 132 are active in commercial products(1/12 is defective). Defective SMs are disabled, allowing the chip to remain usable.
Intel/AMD CPUs: Similarly, multi-core CPUs are sold with subsets of cores enabled, depending on defect distribution during manufacturing.
Cerebras’ Main Advantage
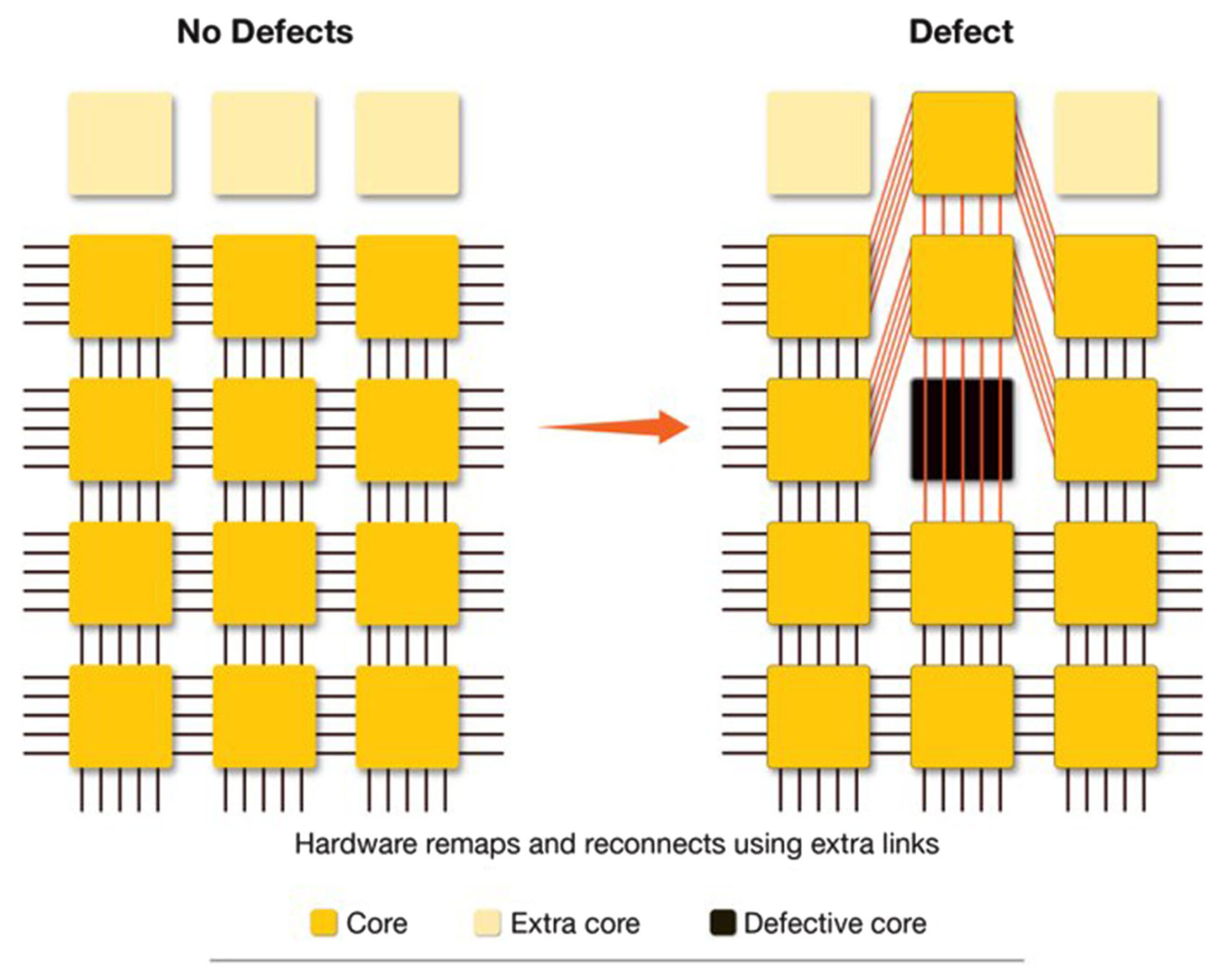
Cerebras addressed the yield challenge by redefining core design and interconnect architecture:
Ultra-Small Cores: Each AI core in the WSE-3 measures 0.05mm², roughly 1% the size of an H100 SM core (~6mm²). A defect in a WSE core disables 100x less silicon area compared to GPUs
Dynamic Routing Architecture: A reconfigurable network reroutes data around defective cores, leveraging redundant pathways and spare cores. This minimizes performance loss without requiring massive redundancy.
Yield Comparison: WSE-3 vs. H100
In order to reach this yield, here are the following things that Cerebras needed to do better than NVIDIA:
Fault-Tolerant Cores: Smaller cores reduce the impact of individual defects.
Resilient Interconnects: The routing system dynamically bypasses defects, maintaining computational integrity.
Efficient Redundancy: Spare cores and intelligent resource allocation minimize overhead.
Speaking of RLHF, there is a neat ebook that talks about RLHF much more in detail here.
Abstract: Reinforcement learning from human feedback (RLHF) has become an important technical and storytelling tool to deploy the latest machine learning systems. In this book, we hope to give a gentle introduction to the core methods for people with some level of quantitative background. The book starts with the origins of RLHF – both in recent literature and in a convergence of disparate fields of science in economics, philosophy, and optimal control. We then set the stage with definitions, problem formulation, data collection, and other common math used in the literature. We detail the popular algorithms and future frontiers of RLHF.
The Swiss Army Llama is designed to facilitate and optimize the process of working with local LLMs by using FastAPI to expose convenient REST endpoints for various tasks, including obtaining text embeddings and completions using different LLMs via llama_cpp, as well as automating the process of obtaining all the embeddings for most common document types, including PDFs (even ones that require OCR), Word files, etc; it even allows you to submit an audio file and automatically transcribes it with the Whisper model, cleans up the resulting text, and then computes the embeddings for it. To avoid wasting computation, these embeddings are cached in SQlite and retrieved if they have already been computed before. To speed up the process of loading multiple LLMs, optional RAM Disks can be used, and the process for creating and managing them is handled automatically for you. With a quick and easy setup process, you will immediately get access to a veritable "Swiss Army Knife" of LLM related tools, all accessible via a convenient Swagger UI and ready to be integrated into your own applications with minimal fuss or configuration required.
vLLM is a fast and easy-to-use library for LLM inference and serving.
vLLM is fast with:
State-of-the-art serving throughput
Efficient management of attention key and value memory with PagedAttention
Optimized CUDA kernels, including integration with FlashAttention and FlashInfer.
Speculative decoding
Chunked prefill
SMOL-GPT is a PyTorch implementation for training your own small LLM from scratch. Designed for educational purposes and simplicity, featuring efficient training, flash attention, and modern sampling techniques.
Features
Minimal Codebase: Pure PyTorch implementation with no abstraction overhead
Tensorgrad is a tensor & deep learning framework. PyTorch meets SymPy.
Tensor diagrams let you manipulate high dimensional tensors are graphs in a way that makes derivatives and complex products easy to understand. The Tensor Cookbook (draft) contains everything you need to know.
Below the Fold
There is an excellent blog post(albeit a bit long) that details about some of the bull, base and bear cases for NVIDIA by going through the technical landscape, competitors and what that might mean and look like in future for NVIDIA.
Some interesting excerpts from the article:
So why does this all matter? Well, instead of trying to battle Nvidia head-on by using a similar approach and trying to match the Mellanox interconnect technology, Cerebras has used a radically innovative approach to do an end-run around the interconnect problem: inter-processor bandwidth becomes much less of an issue when everything is running on the same super-sized chip. You don't even need to have the same level of interconnect because one mega chip replaces tons of H100s.
Groq has taken yet another innovative approach to solving the same fundamental problem. Instead of trying to compete with Nvidia's CUDA software stack directly, they've developed what they call a "tensor processing unit" (TPU) that is specifically designed for the exact mathematical operations that deep learning models need to perform. Their chips are designed around a concept called "deterministic compute," which means that, unlike traditional GPUs where the exact timing of operations can vary, their chips execute operations in a completely predictable way every single time.
And while Amazon is building out data centers featuring billions of dollars of Nvidia GPUs, they are also at the same time investing many billions in other data centers that use these internal chips. They have one cluster that they are bringing online for Anthropic that features over 400k chips.
While Apple's focus seems somewhat orthogonal to these other players in terms of its mobile-first, consumer oriented, "edge compute" focus, if it ends up spending enough money on its new contract with OpenAI to provide AI services to iPhone users, you have to imagine that they have teams looking into making their own custom silicon for inference/training (although given their secrecy, you might never even know about it directly!).
Tiny Corp, which also makes the open-source tinygrad AI software framework), recently announced that he was sick and tired of dealing with AMD's bad drivers, and desperately wanted to be able to to leverage the lower cost AMD GPUs in their TinyBox AI computers (which come in multiple flavors, some of which use Nvidia GPUs, and some of which use AMD GPUS).
It might have just turned out that the relative GPU processing poverty of DeepSeek was the critical ingredient to make them more creative and clever, necessity being the mother of invention and all.
Describe quantization without saying quantization:
DeepSeek cracked this problem by developing a clever system that breaks numbers into small tiles for activations and blocks for weights, and strategically uses high-precision calculations at key points in the network. Unlike other labs that train in high precision and then compress later (losing some quality in the process), DeepSeek's native FP8 approach means they get the massive memory savings without compromising performance. When you're training across thousands of GPUs, this dramatic reduction in memory requirements per GPU translates into needing far fewer GPUs overall.
MoE advantage from DeepSeek:
The beauty of the MOE model approach is that you can decompose the big model into a collection of smaller models that each know different, non-overlapping (at least fully) pieces of knowledge. DeepSeek's innovation here was developing what they call an "auxiliary-loss-free" load balancing strategy that maintains efficient expert utilization without the usual performance degradation that comes from load balancing. Then, depending on the nature of the inference request, you can intelligently route the inference to the "expert" models within that collection of smaller models that are most able to answer that question or solve that task.
R1’s main advantage on RLHF:
With R1, DeepSeek essentially cracked one of the holy grails of AI: getting models to reason step-by-step without relying on massive supervised datasets. Their DeepSeek-R1-Zero experiment showed something remarkable: using pure reinforcement learning with carefully crafted reward functions, they managed to get models to develop sophisticated reasoning capabilities completely autonomously. This wasn't just about solving problems— the model organically learned to generate long chains of thought, self-verify its work, and allocate more computation time to harder problems.
Andrew NG wrote about the key takeaways and a good commentary on DeepSeek as well.
Mathesar is a web application that makes working with PostgreSQL databases both simple and powerful. It empowers users of all technical skill levels to view, edit, query, and collaborate on data with a familiar spreadsheet-like interface—no code needed. It’s self hosted, can be deployed in minutes, and works directly with PostgreSQL databases, schemas, and tables without extra abstractions. The project is 100% open source and maintained by Mathesar Foundation, a 501(c)(3) nonprofit.
Mathesar is as scalable as Postgres and supports any size or complexity of data, making it ideal for workflows involving production databases. It requires minimal setup, and integrates into your existing infrastructure. Because Mathesar is self-hosted, your data never leaves your servers, and access control based on Postgres roles and privileges keeps your database secure without adding unnecessary risk.
lume is a lightweight Command Line Interface and local API server to create, run and manage macOS and Linux virtual machines (VMs) with near-native performance on Apple Silicon, using Apple's Virtualization.Framework.