Do Wide and Deep Networks Learn the Same Things?
Without block structure, they exhibit representation similarity

Articles

Google published an article on the analysis on what deep learning models learn how certain architecture decisions(depth, width) impact on the learning/structure of the model.

They compare the “block structure”(yellow areas in the above figure) for the same model architecture with a deeper model and they find that the block structure might be capturing similar information and amenable for pruning. After a certain depth, this is also one of the reasons why increasing depth does not help model predictive capability.

They also have experiments on the training size and they find out that these block structure also appear with more training data. In the above figure, as the data size increases, the block structures become more and more dominant for the same model. Also, if you look at the above figure, there is a relation between model size and training size where in the paper they claim this ratio is more important than the absolute model size. The paper also delves into random initialization impact if you want to learn more about it.
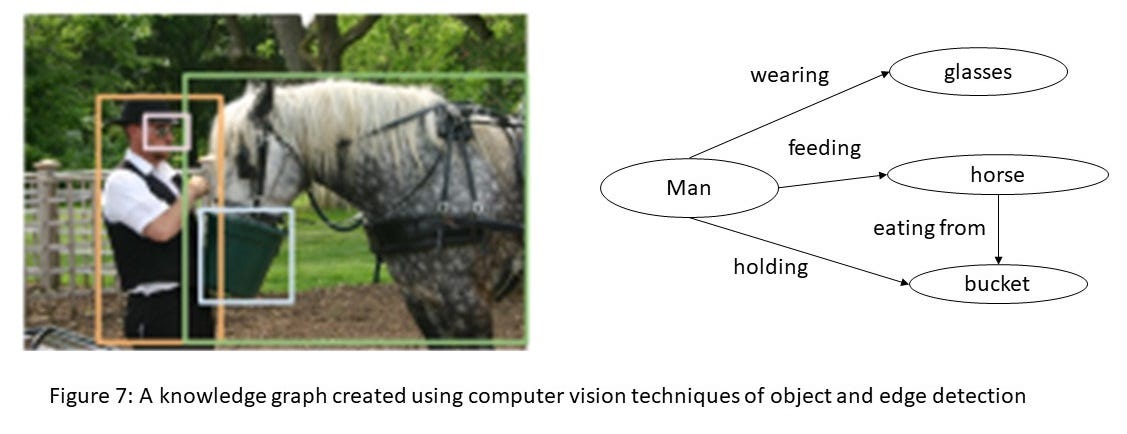
Stanford AI Lab wrote an introduction on knowledge graph and its use cases in different domains. This is a very short and sweet introduction, if you are interested in learning more about in this topic, there is an extensive survey paper and class which is also from Stanford.
Flyte published an article on how they are enabling data lineage through DoIt. Flyte is a workflow management system from Lyft which is tailored towards ML Lifecycle. There is a tutorial as well if you want to see what it looks like.

Twitter rolled back their image crop algorithm through detecting saliency and this post explains how they came up to that decision. All of the code that they used to produce graphs is also available in here. They published a paper that goes through this post in a much more detailed manner.

Nvidia publishes post where they introduce new architectures for Nemo which is a toolkit to build conversational AI capabilities. The above figure shows one of the new architecture that uses Multi-Head Attention called Conformer CTC model.

Linkedin open sourced GreyKite library for forecasting time series. The code is available in here. They showcase a number of use cases that internally responds to their needs.
Papers
Explainable Machine Learning in Deployment is a compilation of how various organizations and engineers are using explainability methods in production successfully. It covers a variety of use cases(finance, computer vision, healthcare, content moderation) and provides various recipes on how explainable workflows can be incorporated into the production deployment.
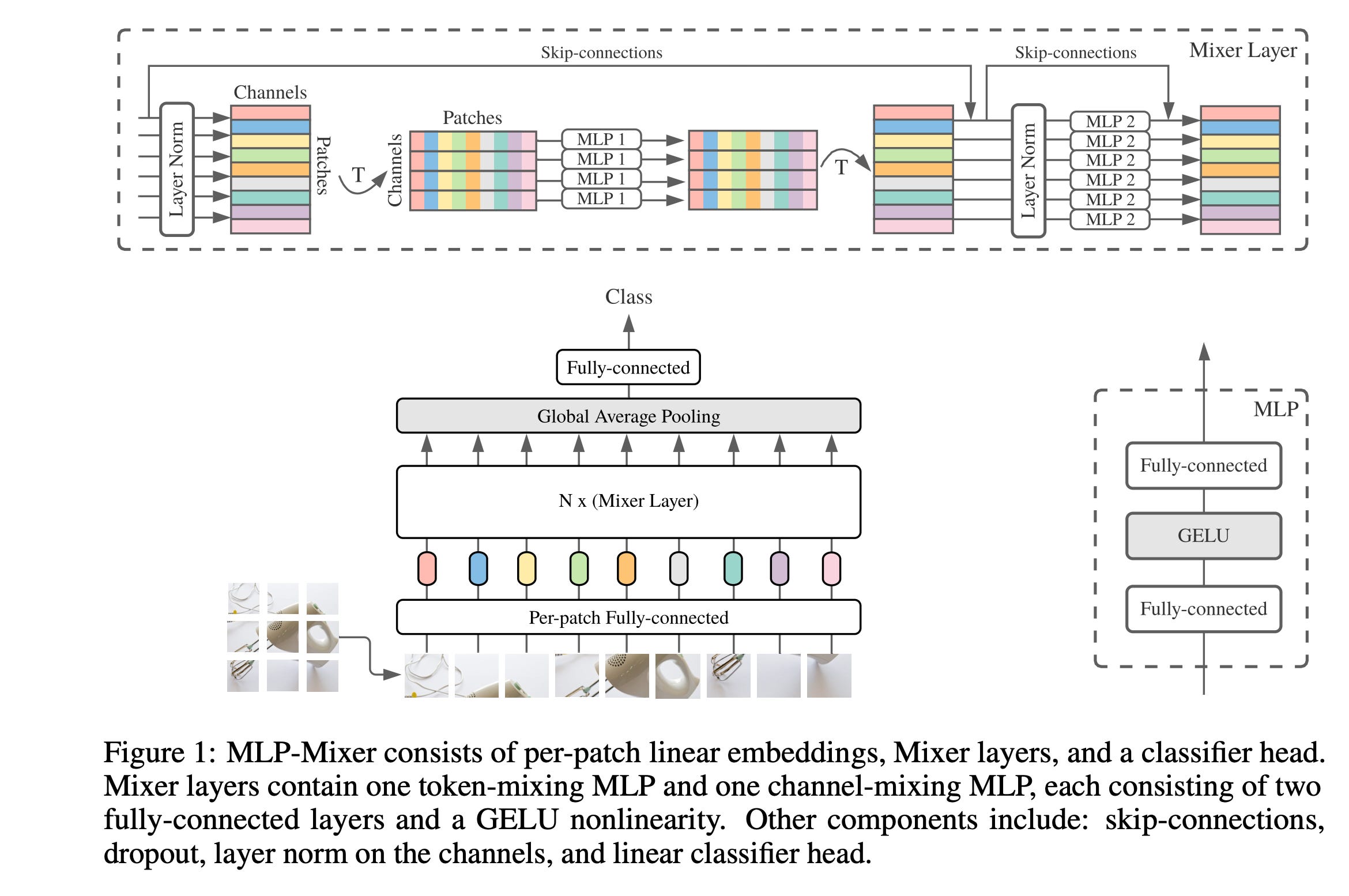
MLP-Mixer: An all-MLP Architecture for Vision is an interesting paper that proposes all MLP(MultiLayer Perceptron) architecture for various vision tasks. Historically, this area has been dominated by CNN(Convolutional Neural Networks) and recently transformers showed better/promising results as well. It is available in both Tensorflow and PyTorch.
Libraries
functorch is PyTorch based library that allows you to write Jax-like programs through functions.
Tune from HuggingFace is a benchmarking library to compare different transformers architecture in a number of different frameworks(PyTorch, Tensorflow, Jax, etc).
KeOps is a library that provides kernel operations for GPU to optimize array operations with autodiff.
LM Memorization is the library that allows you to extract training data from Large Language Models. We covered the paper in this newsletter before.
PyTouch is a library that allows you to build ML models through tactile touch sensing through PyTorch.
SpeechBrain is a toolkit that enables engineers to build SOTA speech ML models for a variety of speech tasks through PyTorch. There are a number of tutorials for the toolkit in here.
Videos
Some people asked in the previous newsletter that is there any place where they can access all of the content for Google I/O 2021 for machine learning. There is a playlist which has all of the main ML content that I watched in the conference: