Differential Private Clustering
HyperDETR, Scenic, Netron, SecML and more

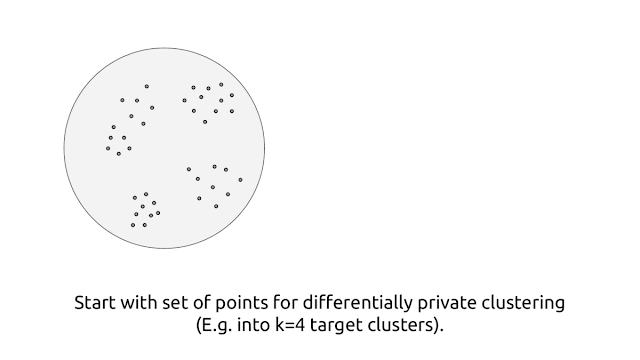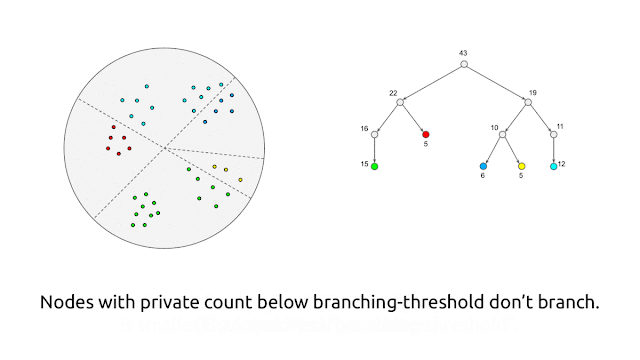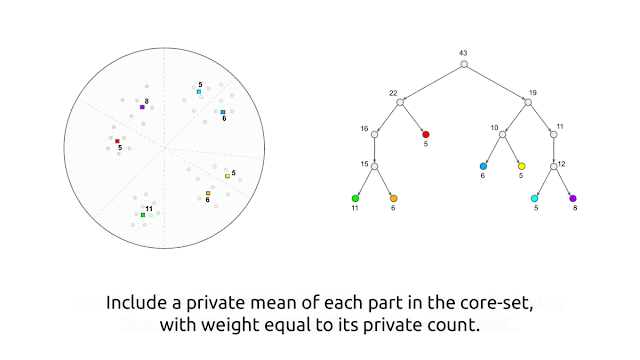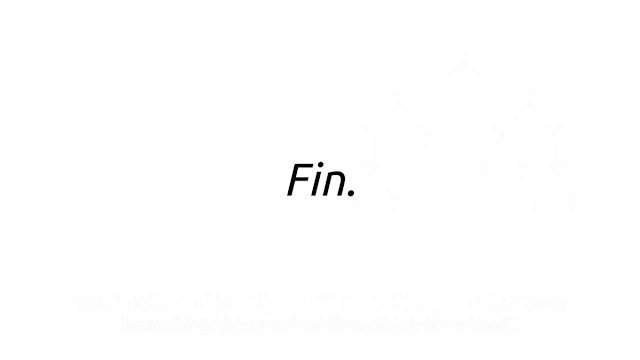
Google published a blog post which proposes a new algorithm for computing representative points (cluster centers) within the framework of differential privacy. It provides a differential mechanism to do clustering.
TLDR:
The algorithm generates the private core-set clusters by using LSH(locality sensitive hashing) using random-projection
After partitioning the observations into “buckets”, the algorithm replaces each bucket by a single weighted observation that is average of the observations.
The way to make it “private”, is to further add noise to the counts and averages of observations into bucket to avoid reveal information of the observations in each bucket.

Apple introduces a variant of popular DETR architecture called HyperDETR. The main idea is to change the architecture is that, while applying transformer in the patches of outputs of convolutional encoder, you also pass this into a convolutional decoder and apply output of transformer and convolutional decoder into a dynamic convolution layer to produce segmentation masks.

Google published a blog post on how they do grammar correction on mobile devices. For model optimization, they use the following techniques:
Shared embedding: Because the input and output of the model are structurally similar (e.g., both are text in the same language), we share some of the model weights between the Transformer encoder and the LSTM decoder, which reduces the model file size considerably without unduly affecting accuracy.
Factorized embedding: The model splits a sentence into a sequence of predefined tokens. To achieve good quality, we find that it is important to use a large vocabulary of predefined tokens, however, this substantially increases the model size. A factorized embedding separates the size of the hidden layers from the size of the vocabulary embedding. This enables us to have a model with a large vocabulary without significantly increasing the number of total weights.
Quantization: To reduce the model size further, we perform post-training quantization, which allows us to store each 32-bit floating point weight using only 8-bits. While this means that each weight is stored with lower fidelity, nevertheless, we find that the quality of the model is not materially affected.
DeepMind released very popular Mujoco library for reinforcement and robotics research and published a blog post. You can both download the library and look at the source code of the project in here.

Google published a blog post announcing a new library for creating baselines of uncertainty and robustness in the deep learning models. The repo has a number of examples in different frameworks like Tensorflow, PyTorch and JAX.

Google published a blog post on how they build a prediction in spreadsheets to enable spreadsheet formulas.

SHAP and Shapley values are very useful, but the documentation of the library rarely covers various visualizations and how this library can be useful for a practical problem. This blog post shows how you can use this powerful library and Shap values in a variety of settings. It can be a very good tutorial or introduction, but if you are already a practitioner of this library, you may still want to skim over to see to cover if there is not something you do not know.
Libraries
MLE-HyperOpt is a library that allows you to hyper-parameter search. The introduction notebook is excellent to check out on how you can use this library.

Facebook Research open-sourced a library that allows compose various parts of transformers called xformers.
Netron helps you to visualize various deep learning models in a nice format. It supports nice visualizations and you can install the application in your machine as well. Some example visualizations are 1, 2 and 3. It supports Tensorflow, Keras, CoreML and ONNX backends and model graphs for visualization.
SecML: A library for Secure and Explainable Machine Learning is a library for secure(robust against adversarial attacks) and explainable(some of the models).
It has the following features:
Wide range of supported ML algorithms. All supervised learning algorithms supported by
scikit-learnare available, as well as Neural Networks (NNs) through PyTorch deep learning platform.Built-in attack algorithms. Evasion and poisoning attacks based on a custom-developed fast solver. In addition, we provide connectors to other third-party Adversarial Machine Learning libraries.
Dense/Sparse data support. We provide full, transparent support for both dense (through
numpylibrary) and sparse data (throughscipylibrary) in a single data structure.Visualize your results. We provide a visualization and plotting framework, based on the widely-known library matplotlib.
Explain your results. Explainable ML methods to interpret model decisions via influential features and prototypes.
Model Zoo. Use our pre-trained models to save time and easily replicate scientific results.
Multi-processing. Do you want to save time further? We provide full compatibility with all the multi-processing features of
scikit-learnandpytorch, along with built-in support of the joblib library.Extensible. Easily create new components, like ML models or attack algorithms, by extending the provided abstract interfaces.
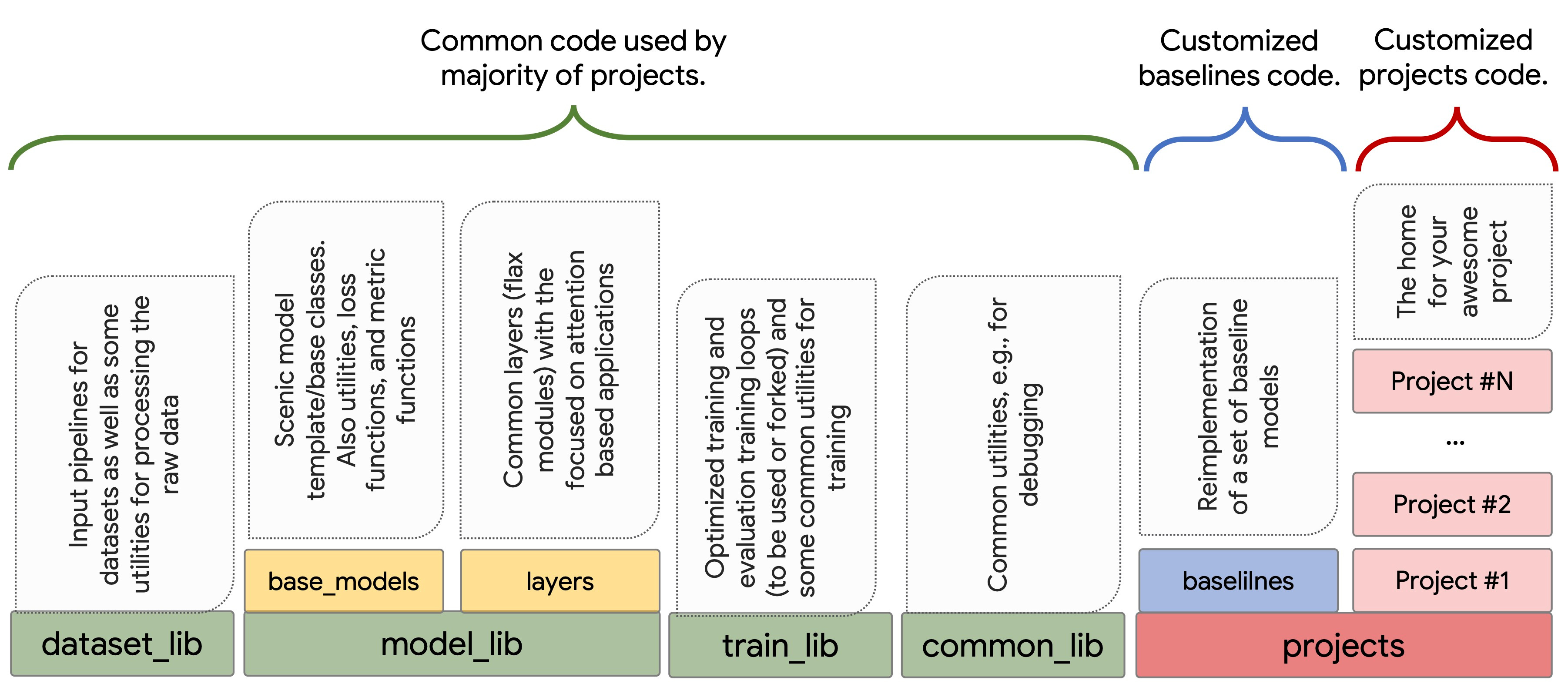
Scenic is a library that is built on JAX and has a strong focus on attention models for computer vision. It has an extensive baselines of models and through JAX, you can compose more sophisticated models for the problem that you are tackling.
Videos
Very entertaining talk on 8-bit optimizers via quantization:
The paper’s title is same with video: 8-bit Optimizers via Block-wise Quantization. The main motivation is that, we are using optimizer 32 bit and they are storing a lot of storage, can we use quantization to make the optimizer memory usage to be smaller? The paper answers this question with yes and explores different ways of using quantization to solve this problem. The code that accompanies paper is also available in here.
A fireside chat between Oriol Vinyals and Geoffrey Hinton is a good conversation to watch over the weekend. Hinton at some point mentions that he is trying new algorithms on the fraction of MNIST dataset in Matlab in his Mac to see if they are any good :)