

DeepSeek's two new reasoning models!
Virtual Personas for LLMs: Anthology


Berkeley researchers wrote a new mechanism to create diverse training dataset for a variety of different “personas” and through these personas to diversity the training corpus being used to train the LLM.
They first motivate this approach by discussing the implications of LLMs being trained on vast text corpora produced by numerous human authors. They reference the concept of "Language Models as Agent Models," which suggests that LLMs can generate text that represents the characteristics of specific agents or individuals when provided with appropriate context. This capability could potentially allow LLMs to approximate the responses of particular human representations rather than a mixture of training dataset voices.
They call this approach called “anthology” which is a way to create various stories for a variety of personas to “condition” LLMs to learn these distinct personas in the system. And its main innovation lies in its use of richly detailed life narratives, or backstories, as conditioning context for LLMs. This approach aims to mitigate limitations of previous methods that relied on broad demographic information for persona creation.
This process goes through the following steps:
Generating a vast set of backstories using LLMs themselves.
Using open-ended prompts like "Tell me about yourself" to create diverse narratives.
Ensuring the backstories cover a wide range of demographic attributes.
These backstories ideally should capture:
Demographic traits
Cultural background
Socioeconomic status
Life philosophies
The LLM is then conditioned with these detailed backstories, allowing it to approximate individual human samples with increased fidelity. This conditioning enables the model to capture nuances beyond simple demographic variables, resulting in more realistic and diverse virtual personas.
To assess the effectiveness of Anthology, the researchers compared it with other conditioning methods in approximating responses to Pew Research Center ATP surveys and various metrics:
Average Wasserstein distance (WD) between response distributions: Measures representativeness
Frobenius norm between correlation matrices: Measures consistency
Cronbach's alpha: Additional measure of internal consistency
Measurement Strategy
They established the following metrics per group:
Randomly dividing the human population into two equal-sized groups
Calculating metrics between these subgroups
Averaging values from 100 iterations
They used two matching methods:
Greedy matching
Maximum weight matching
The evaluation showed that Anthology consistently outperformed other conditioning methods across all metrics for both the Llama-3-70B and Mixtral-8x22B models.

Anthology achieved the closest approximation to human responses in terms of representativeness and consistency.
The greedy matching method generally showed better performance on the average Wasserstein distance across all survey waves.
Through these results, we can conclude that:
The richness of generated backstories eliciting more nuanced responses.
The ability to capture implicit and explicit markers of personal identity beyond simple demographic variables.

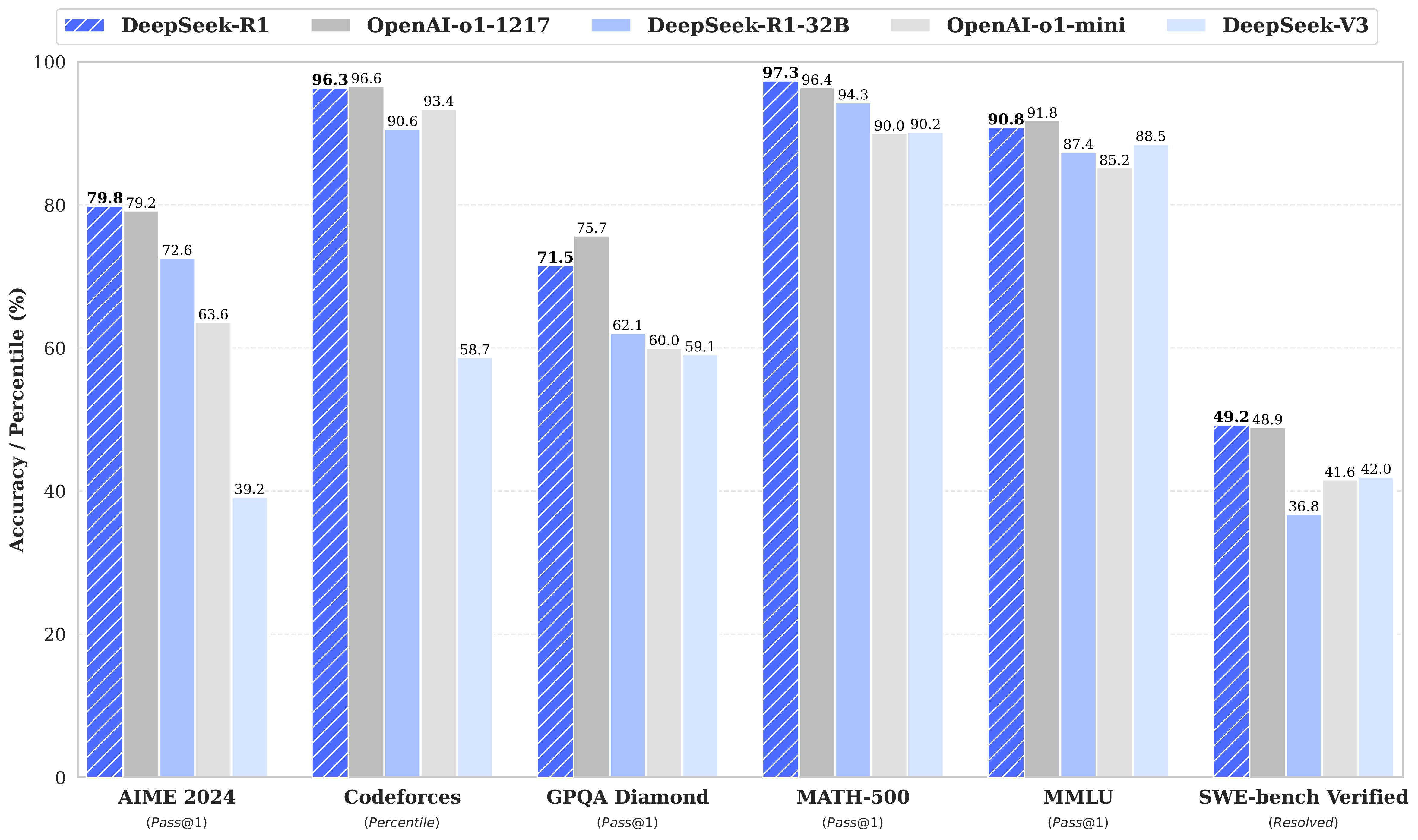
DeepSeek R1 released two new models, their first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning. With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance, they introduce DeepSeek-R1, which incorporates cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks. To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
The paper has more details and to summarize; they have two models as mentioned above:
DeepSeek-R1-Zero:
Developed using large-scale RL without SFT
Demonstrates remarkable reasoning capabilities
Naturally emerges with powerful reasoning behaviors
Challenges include poor readability and language mixing
DeepSeek-R1:
Incorporates multi-stage training and cold-start data before RL
Achieves performance comparable to OpenAI-o1-1217 on reasoning tasks
Addresses challenges faced by DeepSeek-R1-Zero
DeepSeek-R1-Zero has the following capabilities that are used for training the model:
Applies RL directly to the base model (DeepSeek-V3-Base) without SFT
Uses Group Relative Policy Optimization (GRPO) as the RL framework
Employs a rule-based reward system focusing on accuracy and format
Utilizes a simple training template to guide the model's output structure
DeepSeek-R1 has more functionalities to respond some other use cases like cold-start and reasoning oriented capabilities:
Cold Start:
Collects thousands of cold-start data to fine-tune DeepSeek-V3-Base
Reasoning-oriented RL:
Applies RL similar to DeepSeek-R1-Zero
Rejection Sampling and SFT:
Creates new SFT data through rejection sampling on the RL checkpoint
Combines with supervised data from DeepSeek-V3 in various domains
Retrains the DeepSeek-V3-Base model
Additional RL:
Performs another round of RL considering prompts from all scenarios
Libraries

Pyper is a flexible framework for concurrent and parallel data-processing, based on functional programming patterns. Used for 🔀 ETL Systems, ⚙️ Data Microservices, and 🌐 Data Collection
Key features:
💡Intuitive API: Easy to learn, easy to think about. Implements clean abstractions to seamlessly unify threaded, multiprocessed, and asynchronous work.
🚀 Functional Paradigm: Python functions are the building blocks of data pipelines. Let's you write clean, reusable code naturally.
🛡️ Safety: Hides the heavy lifting of underlying task execution and resource clean-up. No more worrying about race conditions, memory leaks, or thread-level error handling.
⚡ Efficiency: Designed from the ground up for lazy execution, using queues, workers, and generators.
✨ Pure Python: Lightweight, with zero sub-dependencies.

structured-logprobs is an open-source Python library that enhances OpenAI's structured outputs by providing detailed information about token log probabilities.

This library is designed to offer valuable insights into the reliability of an LLM's structured outputs. It works with OpenAI's Structured Outputs, a feature that ensures the model consistently generates responses adhering to a supplied JSON Schema. This eliminates concerns about missing required keys or hallucinating invalid values.

DataFusion is an extensible query engine written in Rust that uses Apache Arrow as its in-memory format.
DataFusion Python offers a Python interface for SQL and DataFrame queries.
DataFusion Ray provides a distributed version of DataFusion that scales out on Ray clusters.
DataFusion Comet is an accelerator for Apache Spark based on DataFusion.
“Out of the box,” DataFusion offers SQL and Dataframe APIs, excellent performance, built-in support for CSV, Parquet, JSON, and Avro, extensive customization, and a great community. Python Bindings are also available.
DataFusion features a full query planner, a columnar, streaming, multi-threaded, vectorized execution engine, and partitioned data sources. You can customize DataFusion at almost all points including additional data sources, query languages, functions, custom operators and more. See the Architecture section for more details.
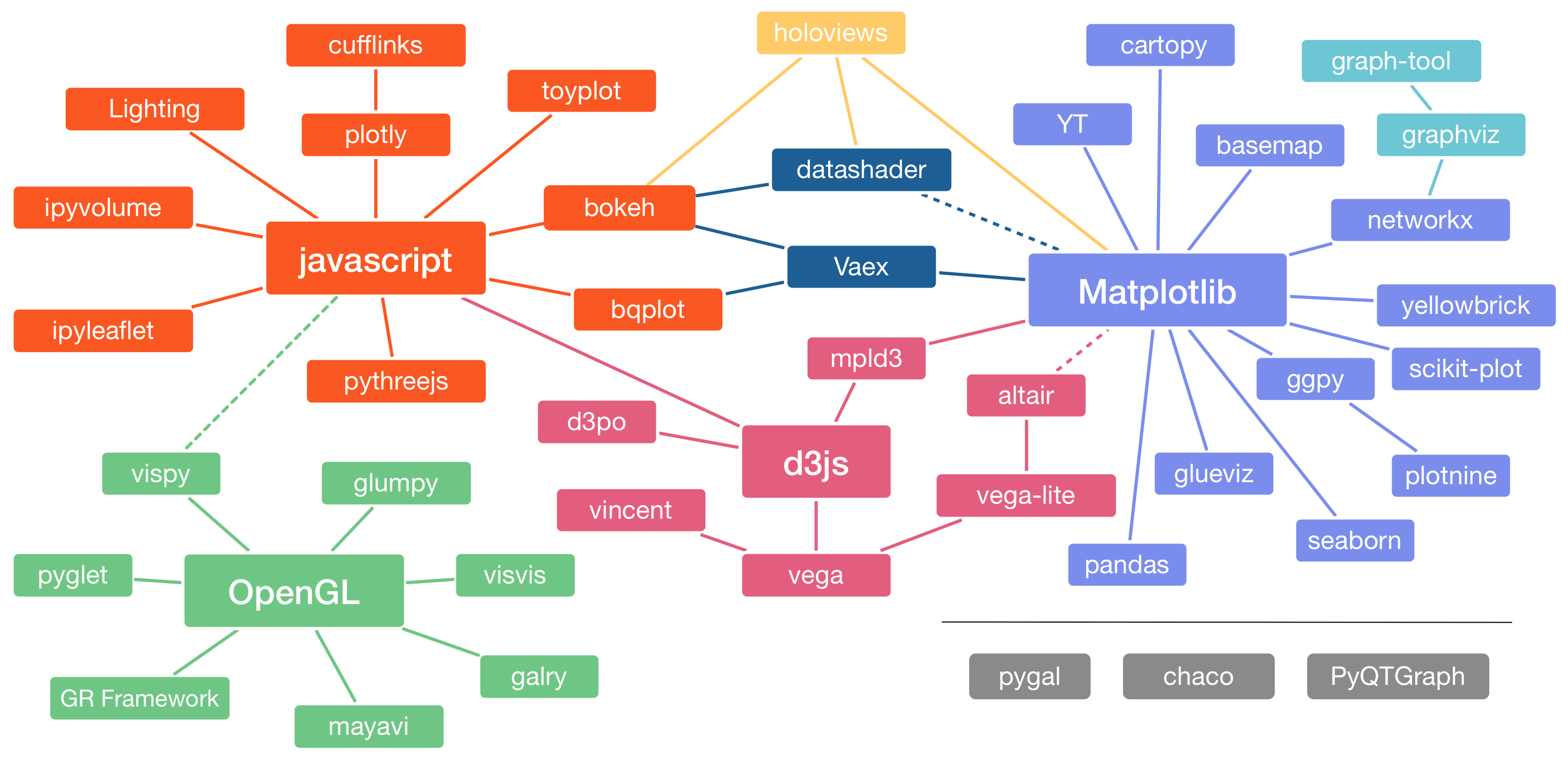
The Python visualization landscape can seem daunting at first. PyViz attempts to shine light on common patterns and use cases, comparing or discussing multiple plotting libraries. Note that some of the projects discussed in the overviews are no longer maintained, so be sure to check the list of dormant projects before choosing that library.
It has an excellent categories(core, high-level, geospatial, graphs, tables, dashboard, color mapping) libraries for visualization as well.
Pathway's AI Pipelines allow you to quickly put in production AI applications that offer high-accuracy RAG and AI enterprise search at scale using the most up-to-date knowledge available in your data sources. It provides you ready-to-deploy LLM (Large Language Model) App Templates. You can test them on your own machine and deploy on-cloud (GCP, AWS, Azure, Render,...) or on-premises.
The apps connect and sync (all new data additions, deletions, updates) with data sources on your file system, Google Drive, Sharepoint, S3, Kafka, PostgreSQL, real-time data APIs. They come with no infrastructure dependencies that would need a separate setup. They include built-in data indexing enabling vector search, hybrid search, and full-text search - all done in-memory, with cache.

LangWatch is a visual interface for DSPy and a complete LLM Ops platform for monitoring, experimenting, measuring and improving LLM pipelines, with a fair-code distribution model.

Phidata is a framework for building multi-modal agents, use phidata to:
Build multi-modal agents with memory, knowledge, tools and reasoning.
Build teams of agents that can work together to solve problems.
Chat with your agents using a beautiful Agent UI.

Chonkie is a very opinionated library, and it all stems from innate human mortality. We are all going to die one day, and we have no reason to waste time figuring out how to chunk documents. Just use Chonkie.
Chonkie needs to be and always adheres to be:
Simple: We care about how simple it is to use Chonkie. No brainer.
Fast: We care about your latency. No time to waste.
Lightweight: We care about your memory. No space to waste.
Flexible: We care about your customization needs. Hassle free.
Chunking Explained
Chunking is the process of breaking down a text into smaller, more manageable pieces, that can be used for RAG applications.
An ideal chunk is one that is:
Reconstructable: A chunk should be part of the whole text, such that combining chunks should give you the original text back.
Independent: It should be a standalone unit tackling only one idea, i.e., removing it from the chunk should not remove important information from the original text.
Sufficient: It should be long enough to be meaningful, i.e., it should contain enough information to be useful.
yek is a fast Rust based tool to read text-based files in a repository or directory, chunk them, and serialize them for LLM consumption. By default, the tool:
Uses
.gitignorerules to skip unwanted files.Uses the Git history to infer what files are important.
Infers additional ignore patterns (binary, large, etc.).
Splits content into chunks based on either approximate "token" count or byte size.
Automatically detects if output is being piped and streams content instead of writing to files.
Supports processing multiple directories in a single command.
Configurable via a
yek.tomlfile.
Below the Fold
uv is an extremely fast Python package and project manager, written in Rust.

Installing Trio's dependencies with a warm cache.
Highlights
🚀 A single tool to replace
pip,pip-tools,pipx,poetry,pyenv,twine,virtualenv, and more.⚡️ 10-100x faster than
pip.🐍 Installs and manages Python versions.
🛠️ Runs and installs Python applications.
❇️ Runs single-file scripts, with support for inline dependency metadata.
🗂️ Provides comprehensive project management, with a universal lockfile.
🔩 Includes a pip-compatible interface for a performance boost with a familiar CLI.
🏢 Supports Cargo-style workspaces for scalable projects.
💾 Disk-space efficient, with a global cache for dependency deduplication.
⏬ Installable without Rust or Python via
curlorpip.🖥️ Supports macOS, Linux, and Windows.
Nyxelf is a powerful tool for analyzing malicious Linux ELF binaries, offering both static and dynamic analysis. It combines tools like readelf, objdump, and pyelftools for static analysis with a custom sandbox for dynamic analysis in a controlled environment using QEMU, a minimal Buildroot-generated image, and strace. With Nyxelf, you can gain deep insights into executable files, including unpacking, syscall tracing, and process/file activity monitoring, all presented through an intuitive GUI powered by pywebview.
Git is hard: screwing up is easy, and figuring out how to fix your mistakes is hard. Git documentation has this chicken and egg problem where you can't search for how to get yourself out of a mess, unless you already know the name of the thing you need to know about in order to fix your problem.