
This week, we will do a deep dive for Deep Seek R1 paper and outline the technical innovations in this paper and the model. Without further ado, let’s get to it!
DeepSeek-R1 is a open-source language model developed by DeepSeek-AI, designed to rival proprietary models like OpenAI’s o1 series in reasoning, coding, and mathematical problem-solving. Released on January 20, 2025, it introduces a novel reinforcement learning (RL)-centric training paradigm that eliminates dependency on supervised fine-tuning (SFT) and achieves state-of-the-art performance at a fraction of the computational cost.
Key Innovations
RL-First Training: Direct application of RL to pre-trained base models, bypassing SFT.
Group Relative Policy Optimization (GRPO): A compute-efficient RL algorithm that reduces reliance on reward models.
Cold-Start Data Engineering: Curated datasets to stabilize RL training and improve readability.
Distillation: Transferring reasoning capabilities to smaller models (1.5B–70B parameters) with minimal performance loss.
Especially, they emphasize to main innovations which is large scale reinforcement learning and knowledge distillation.
Post-Training: Large-Scale Reinforcement Learning on the Base Model
They directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
They introduce their pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities. They believe the pipeline will benefit the industry by creating better models.
Distillation: Smaller Models Can Be Powerful Too
They demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
Using the reasoning data generated by DeepSeek-R1, they fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. They open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
They have released two different models; one of them is base and other one is RL + Cold Start and the second model is accommodating the base model’s main limitation which is readability.
Architecture and Base Model
DeepSeek-V3-Base
Backbone: 671B-parameter transformer with Mixture-of-Experts (MoE) architecture (128 experts, 37B activated parameters per token).
Pretraining Data: 15T tokens from web text, code repositories (GitHub), and scientific papers.
Key Features:
Dynamic Expert Routing: Token-based gating for task specialization.
Multi-Head Latent Attention (MLA): Compresses attention heads into latent vectors to reduce memory overhead.
Training Methodology
DeepSeek-R1-Zero: Pure RL Training
Objective: Incentivize reasoning without labeled data.
Algorithm: Group Relative Policy Optimization (GRPO):
Mechanics:




Through this approach, it does require 40% fewer GPU hours than Proximal Policy Optimization (PPO) and avoids reward hacking by using rule-based rewards.
Reward Design:
Accuracy Reward: Validates answers via symbolic checks (e.g., SymPy for math, unit tests for code).
Format Reward: Enforces structured outputs (e.g., `<think>...</think>` for reasoning steps).
Emergent Behaviors:
Self-Verification: The model revisits and corrects earlier reasoning steps.
Reflection: Generates alternative approaches to complex problems.




DeepSeek-R1: Cold-Start RL
Cold-Start Data:
800K high-quality reasoning examples (e.g., step-by-step math proofs, code solutions).
Generated via few-shot prompting and manual curation.
Training Pipeline:
Stage 1 (Cold-Start SFT): Fine-tune DeepSeek-V3-Base on curated data.
Stage 2 (Reasoning RL): Apply GRPO with language consistency rewards.
Stage 3 (SFT Refinement): Generate 600K trajectories via rejection sampling.
Stage 4 (Alignment RL): Optimize for human preferences using hybrid rewards.
Language Consistency Reward:
Penalizes mixed-language outputs by measuring target language token ratio.
Technical Innovations
Group Relative Policy Optimization (GRPO)
Advantages Over PPO:
Eliminates critic model training.
Reduces reward variance via group-based normalization.
Cold-Start Data Engineering
Filtering Criteria:
Readability: Discard outputs without markdown formatting or summaries.
Language Consistency: Enforce monolingual responses.
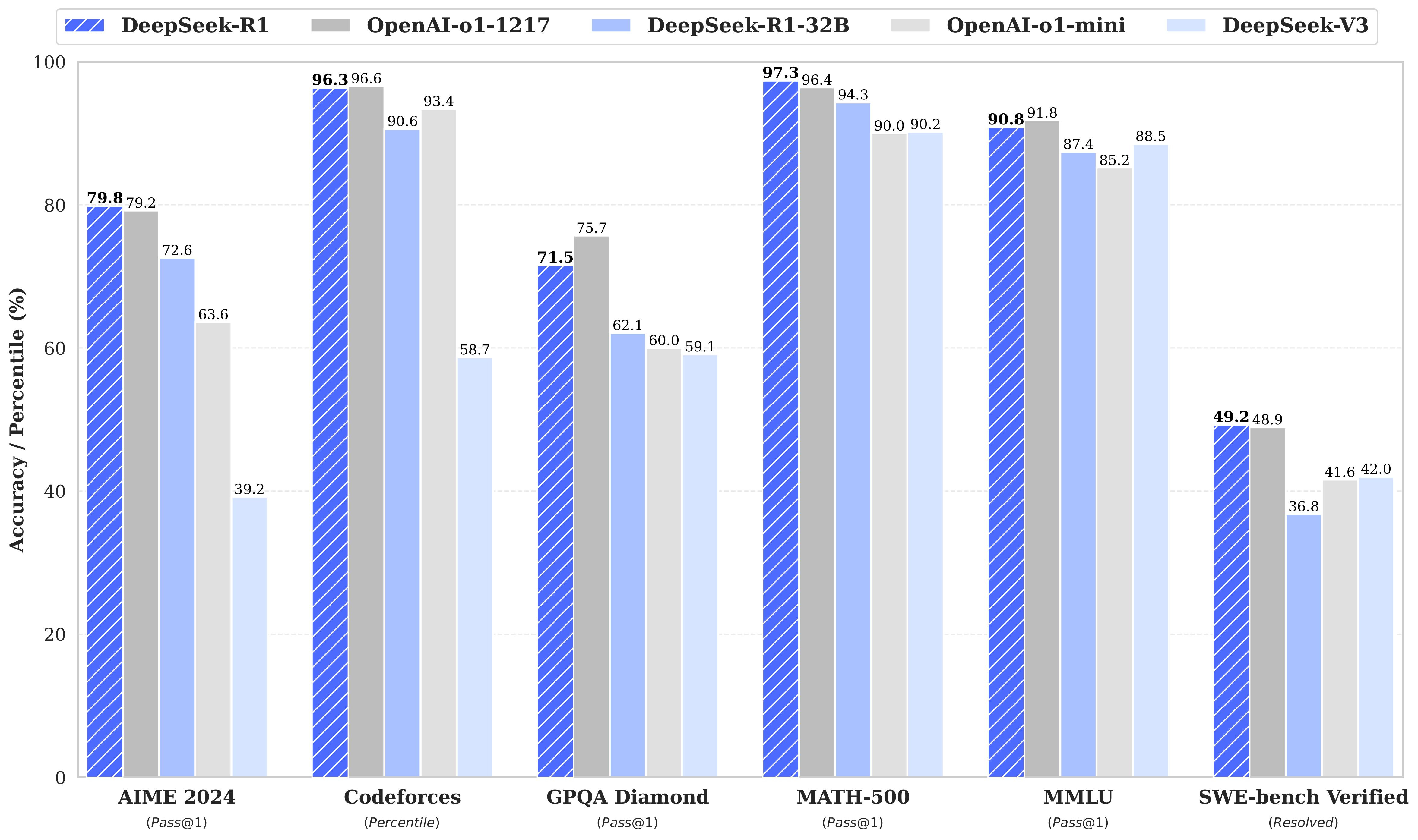
They are very comparable with OpenAI o1 model across many dimensions:
As the previous paper and model, this model is also available in GitHub.
Libraries
Retrieval-Augmented Generation (RAG) is a technique to search for information based on a user query and provide the results as reference for an AI answer to be generated. This technique is an important part of most LLM-based tools and the majority of RAG approaches use vector similarity as the search technique. GraphRAG uses LLM-generated knowledge graphs to provide substantial improvements in question-and-answer performance when conducting document analysis of complex information. Baseline RAG[1] was created to help solve this problem, but we observe situations where baseline RAG performs very poorly. For example:
Baseline RAG struggles to connect the dots. This happens when answering a question requires traversing disparate pieces of information through their shared attributes in order to provide new synthesized insights.
Baseline RAG performs poorly when being asked to holistically understand summarized semantic concepts over large data collections or even singular large documents.
GraphRAG project is a data pipeline and transformation suite that is designed to extract meaningful, structured data from unstructured text using the power of LLMs.
To learn more about GraphRAG and how it can be used to enhance your LLM's ability to reason about your private data, please visit the Microsoft Research Blog Post.
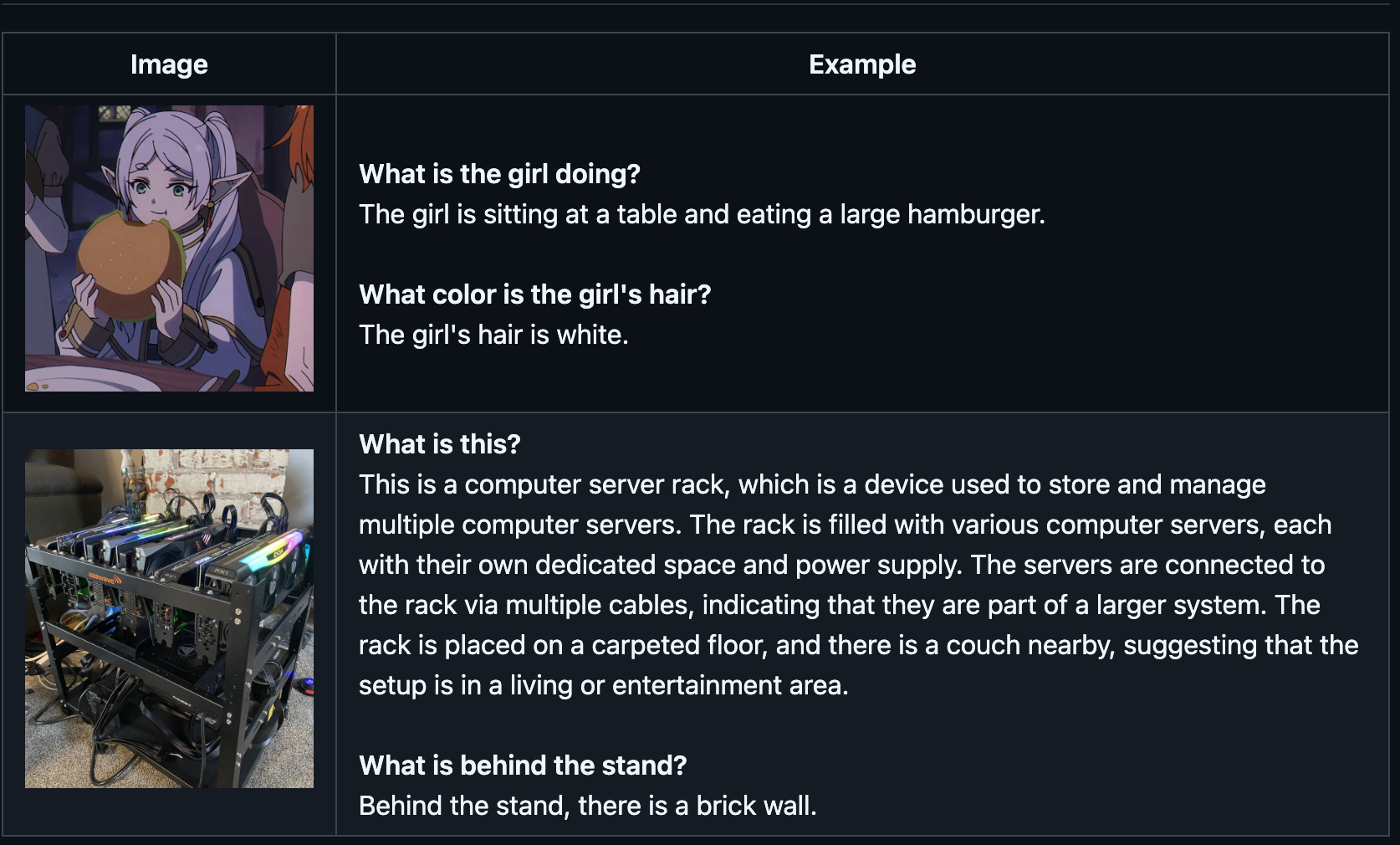
Moondream is a highly efficient open-source vision language model that combines powerful image understanding capabilities with a remarkably small footprint. It's designed to be versatile and accessible, capable of running on a wide range of devices and platforms.
The project offers two model variants:
Moondream 2B: The primary model with 2 billion parameters, offering robust performance for general-purpose image understanding tasks including captioning, visual question answering, and object detection.
Moondream 0.5B: A compact 500 million parameter model specifically optimized as a distillation target for edge devices, enabling efficient deployment on resource-constrained hardware while maintaining impressive capabilities.
Below The Fold

Plate is a powerful toolkit that makes it easier for you to develop with Slate, a popular framework for building text editors. Plate focuses on four main areas: Core, Plugins, Primitives and Components.
The heart of Plate is its plugin system, designed for both slate and slate-react, with support for server-side rendering. It helps keep your project organized and efficient by separating different functionalities and keeping things clean. The core functionality is available in vanilla JavaScript, allowing for server-side rendering and non-React usage