

Composable Models, Model Ensembles
When Multilingual models beat bilingual models

Articles
Strong AI Requires Autonomous Building of Composable Models article tells us to build the large scale models in a way that would be composable. The main premise of the article is that models have to be very rich and deep in terms of knowledge representation and this requires that AI models have to be trained in a different simulated environments like humans are. To measure learning, we need visibility on the internal process of AI models to ensure that they are actually learning rather than overfitting.

Google published a blog post on model ensembles and cascades. Ensemble/cascade-based models obtain superior efficiency and accuracy over state-of-the-art models from several standard architecture families in the blog post.
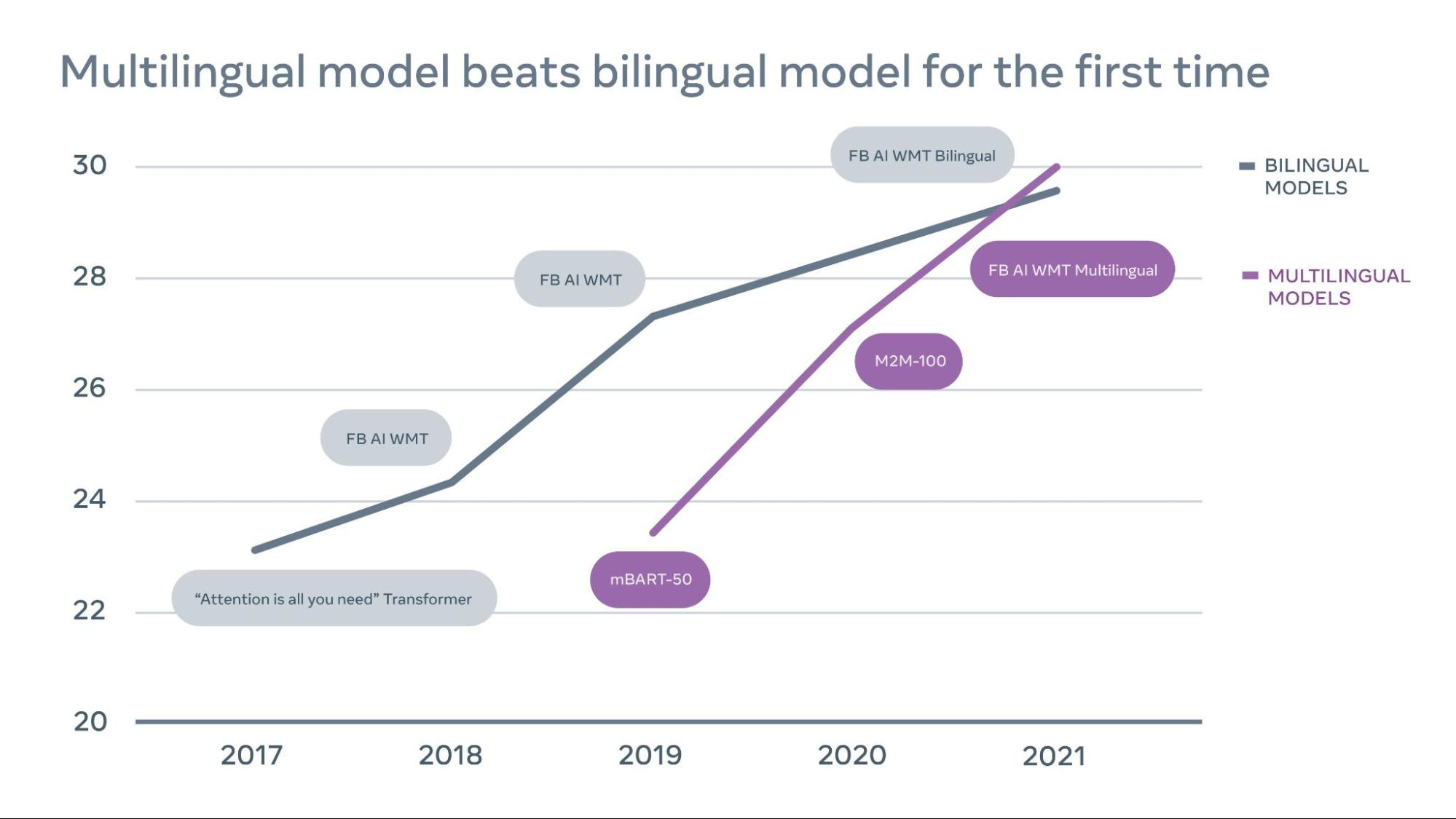
Multilingual models from Facebook beats bilingual models in a blog post.
To build a universal translator, we believe the MT field should shift away from bilingual models and advance toward multilingual translation — where a single model translates many language pairs at once, including both low-resource (e.g., Icelandic to English) and high-resource (e.g., English to German). Multilingual translation is an appealing approach — it’s simpler, more scalable, and better for low-resource languages. But until now, this approach couldn’t provide results for high-resource language pairs that were as good as specially trained bilingual models for those language pairs. As a result, delivering quality translations across many languages has generally involved using a combination of individual bilingual models, and low-resource languages have lagged behind.

Walmart wrote about their recommender systems in this blog post.

In Mozrt, there are two candidate generation algorithms.
Collaborative filtering roughly selects learning content candidates by associate view history.
Content-based similarity selects another group of candidates by content keywords similarity.
Each content has a unique content id. They use content id as “word” and sequence of associate clicks as “sentence” and run a skip-graph neural language model to acquire embedding as content related input of deep learning ranking algorithm.
DeepFM algorithm outputs the final rank for learning content candidates. The wide component, a general linear regression with factorization machine parameter estimation, is responsible for memorizing historical information. The deep component, a feed-forward neural network, provides strong generalization ability. These two components work together to predict the learning content the associate needs when they interact with the app with high accuracy.
Fidelity wrote about Stoke no-code configuration system detailing how it works in a blog post.
Libraries
cockpit is a visual and statistical debugger specifically designed for deep learning. Successfully training such a network usually requires either years of intuition or expensive parameter searches involving lots of trial and error. Traditional debuggers provide only limited help: They can find syntactical errors but not training bugs such as ill-chosen learning rates. Cockpit offers a closer, more meaningful look into the training process with multiple well-chosen instruments.
Its documentation is currently sparse, but useful if you want to understand various approaches.
torchgeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.

mend is a library that implements MEND paper which is an efficient approach to editing very large (10 billion+ parameter) neural networks, whose acronym is Model Editor Networks with Gradient Decomposition or MEND. To do so, MEND treats the model editing problem itself as a learning problem, using a relatively small edit dataset to learn model editor networks that can correct model errors using only a single input-output pair. MEND leverages the fact that gradients with respect to the fully-connected layers in neural networks are rank-1, enabling a parameter-efficient architecture that represents this gradient transform.

FOST (Forecasting open source tool) aims to provide an easy-use tool for spatial-temporal forecasting. The users only need to organize their data into a certain format and then get the prediction results with one command. FOST automatically handles the missing and abnormal values, and captures both spatial and temporal correlations efficiently.
Embeddinghub is a database built for machine learning embeddings. It is built with four goals in mind:
Store embeddings durably and with high availability
Allow for approximate nearest neighbor operations
Enable other operations like partitioning, sub-indices, and averaging
Manage versioning, access control, and rollbacks painlessly
Toonify is a repository that uses GANs to make the face images to look like cartoon characters. It has a nice demo page in here.
Kaggle Solutions is an aggregate page that compiles a number of Kaggle compeititons in a single page.