
Articles
LLM Arena
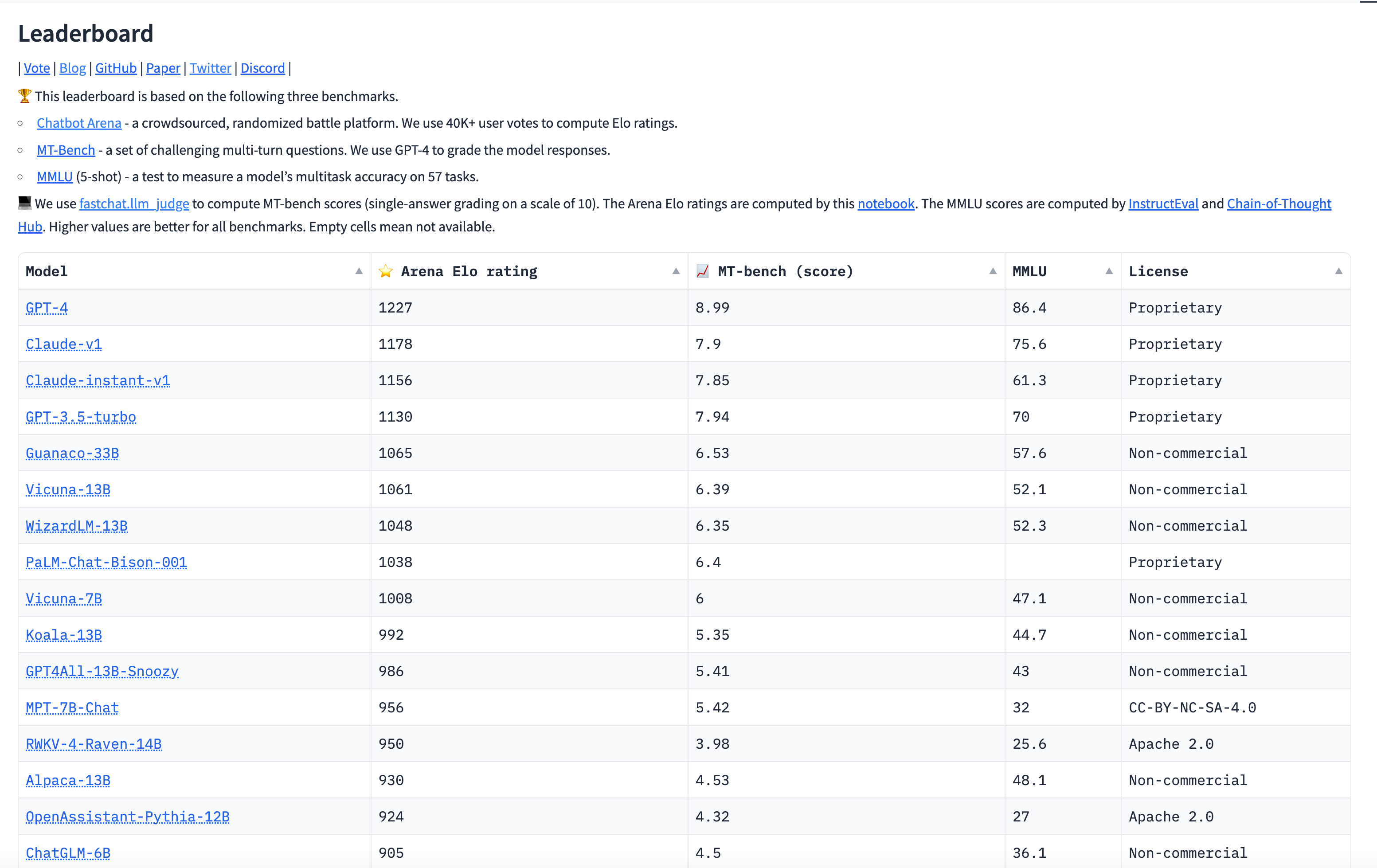
You want to use a chatbot or LLM, but you do not know which one to pick? Or you simply want to compare various LLMs in terms of capability? HuggingFace leaderboard might be the leaderboard that you are looking for. It uses FastChat under the hood for evaluation.
It does Elo Score computation for pair-wise models:

Andrej Karpathy had an excellent talk called State of GPT, I will cover some of the slides below, but I highly recommend watching out the full talk both from technical details of the GPT series of models, but also state of the union where he gives a number of development comparing to GPT1, 2, 3 and 4 series and how the GPT is evolving over the years(2019-2023).

Data Collection: Download a large amount of publicly available data

Preprocessing: Tokenization; transform all text into one very long list of integers.

2 Example Models:
GPT3
Vocabulary Size: 50257
Context Length: 2048
Parameter Count: 175B
Training Data Set Size: 300B
LLama
Vocabulary Size: 32000
Context Length: 2048
Parameter Count: 65B
Training Data Set Size: 1.4T

Pretraining: Each cell only “sees” cells in its row and only cells before it(context) to predict the next cell(prediction)

He then talks about base models and assistant models(fine-tuned ones). In here, the distinction is that base models want to complete documents(with a given context) where assistant models can be used/tricked into performing tasks with prompt engineering.

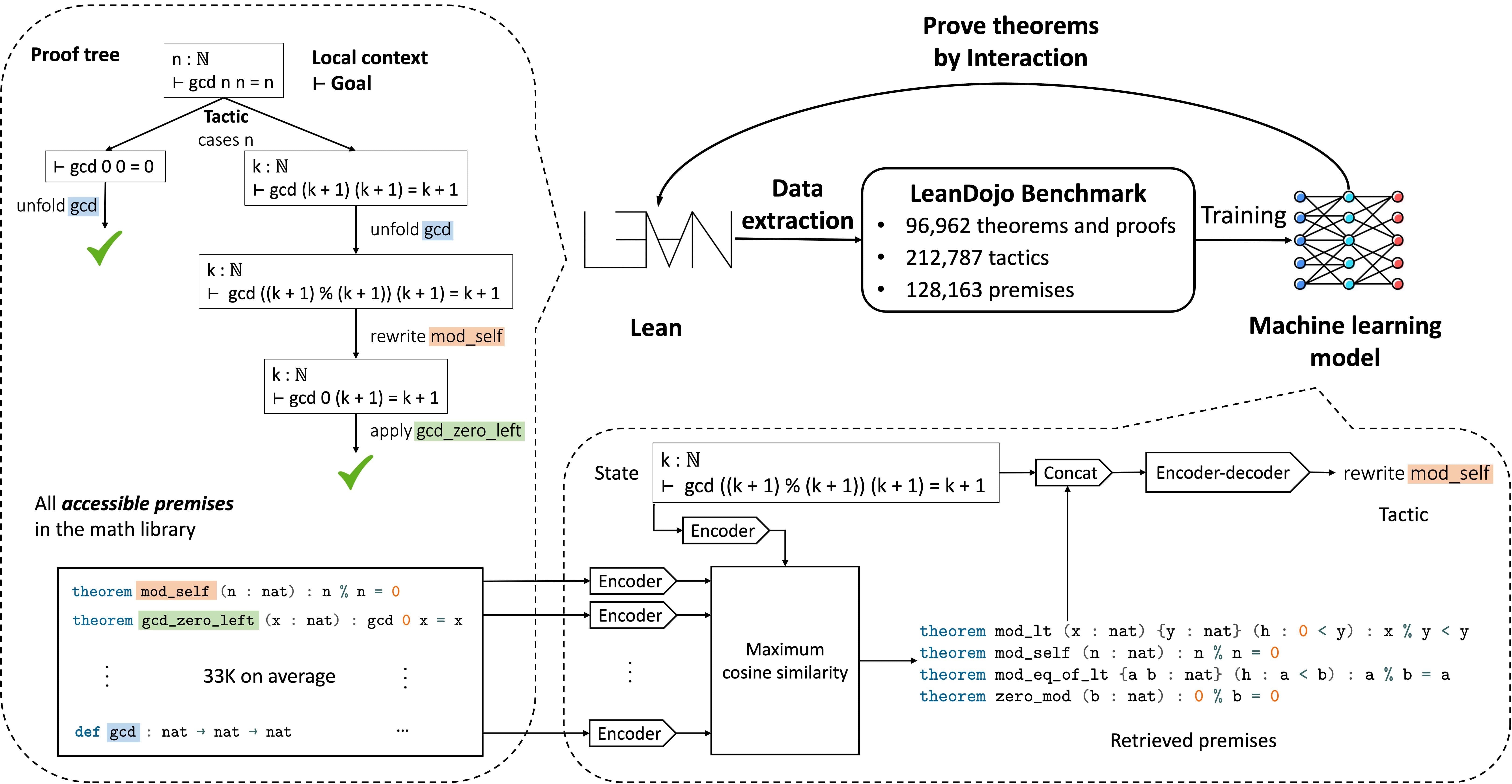
Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. Models are also available in GitHub.
Libraries
QuestDB is an open-source time-series database for high throughput ingestion and fast SQL queries with operational simplicity. It supports schema-agnostic ingestion using the InfluxDB line protocol, PostgreSQL wire protocol, and a REST API for bulk imports and exports.
QuestDB is well suited for financial market data, application metrics, sensor data, real-time analytics, dashboards, and infrastructure monitoring.
QuestDB implements ANSI SQL with native time-series SQL extensions. These SQL extensions make it simple to correlate data from multiple sources using relational and time-series joins. We achieve high performance by adopting a column-oriented storage model, parallelized vector execution, SIMD instructions, and low-latency techniques. The entire codebase is built from the ground up in Java and C++, with no dependencies and zero garbage collection.
ChatRWKV is like ChatGPT but powered by my RWKV (100% RNN) language model, which is the only RNN (as of now) that can match transformers in quality and scaling, while being faster and saves VRAM.
The PromptCraft-Robotics repository serves as a community for people to test and share interesting prompting examples for large language models (LLMs) within the robotics domain.
pgmigrate is a modern Postgres migrations CLI and golang library. It is designed for use by high-velocity teams who practice continuous deployment. The goal is to make migrations as simple and reliable as possible.
LLM-judge prompts to evaluate your models with LLM-as-a-judge. MT-bench is a set of challenging multi-turn open-ended questions for evaluating chat assistants. To automate the evaluation process, we prompt strong LLMs like GPT-4 to act as judges and assess the quality of the models' responses.
ShortGPT is a powerful framework for automating content creation. It simplifies video creation, footage sourcing, voiceover synthesis, and editing tasks.
🎞️ Automated editing framework: Streamlines the video creation process with an LLM oriented video editing language.
📃 Scripts and Prompts: Provides ready-to-use scripts and prompts for various LLM automated editing processes.
🗣️ Voiceover / Content Creation: Supports multiple languages including English 🇺🇸, Spanish 🇪🇸, Arabic 🇦🇪, French 🇫🇷, Polish 🇵🇱, German 🇩🇪, Italian 🇮🇹, and Portuguese 🇵🇹.
🔗 Caption Generation: Automates the generation of video captions.
🌐🎥 Asset Sourcing: Sources images and video footage from the internet, connecting with the web and Pexels API as necessary.
🧠 Memory and persistency: Ensures long-term persistency of automated editing variables with TinyDB.
Workshops & Classes
Tabular data has long been overlooked despite its dominant presence in data-intensive systems. By learning latent representations from (semi-)structured tabular data, pretrained table models have shown preliminary but impressive performance for semantic parsing, question answering, table understanding, and data preparation. Considering that such tasks share fundamental properties inherent to tables, representation learning for tabular data is an important direction to explore further. These works also surfaced many open challenges such as finding effective data encodings, pretraining objectives and downstream tasks.
The Table Representation Learning workshop is the first workshop in this emerging research area and has the following main goals: 1) motivating tabular data as a first-class modality for representation learning and further shaping this area, 2) show-casing impactful applications of pretrained table models and discussing future opportunities thereof, and 3) facilitating discussion and collaboration across the machine learning, natural language processing, and data management communities.
Google created a new learning path guides you through a curated collection of content on generative AI products and technologies, from the fundamentals of Large Language Models to how to create and deploy generative AI solutions on Google Cloud.
Reinforcement learning is one powerful paradigm for doing so, and it is relevant to an enormous range of tasks, including robotics, game playing, consumer modeling and healthcare. This class will provide a solid introduction to the field of reinforcement learning and students will learn about the core challenges and approaches, including generalization and exploration. Through a combination of lectures, and written and coding assignments, students will become well versed in key ideas and techniques for RL. Assignments will include the basics of reinforcement learning as well as deep reinforcement learning — an extremely promising new area that combines deep learning techniques with reinforcement learning.
Natural language processing (NLP) or computational linguistics is one of the most important technologies of the information age. Applications of NLP are everywhere because people communicate almost everything in language: web search, advertising, emails, customer service, language translation, virtual agents, medical reports, politics, etc. In the last decade, deep learning (or neural network) approaches have obtained very high performance across many different NLP tasks, using single end-to-end neural models that do not require traditional, task-specific feature engineering. In this course, students will gain a thorough introduction to cutting-edge research in Deep Learning for NLP. Through lectures, assignments and a final project, students will learn the necessary skills to design, implement, and understand their own neural network models, using the Pytorch framework.
HuggingFace has a new class called Audio where they talk about Text to Speech(TTS).
The task we will study in this unit is called “Text-to-speech” (TTS). Models capable of converting text into audible human speech have a wide range of potential applications:
Assistive apps: think about tools that can leverage these models to enable visually-impaired people to access digital content through the medium of sound.
Audiobook narration: converting written books into audio form makes literature more accessible to individuals who prefer to listen or have difficulty with reading.
Virtual assistants: TTS models are a fundamental component of virtual assistants like Siri, Google Assistant, or Amazon Alexa. Once they have used a classification model to catch the wake word, and used ASR model to process your request, they can use a TTS model to respond to your inquiry.
Entertainment, gaming and language learning: give voice to your NPC characters, narrate game events, or help language learners with examples of correct pronunciation and intonation of words and phrases.
I recommend checking out this conversation between Chris Manning and Andrew NG: