

ChatGPT Plugins, NVIDIA launches Prismer
Google launches PaLM-E, State of Competitive ML in 2022

Articles

OpenAI published ChatGPT plugins for a variety of different applications. This enables ChatGPT to be available as part of other types of applications like Kayak, Instacart and OpenTable applications to increate the adoption for a variety of different applications. Especially, on browsing plugin that they have can be a new and very elevated browsing experience especially on finding information and combining different types of information for research oriented tasks.
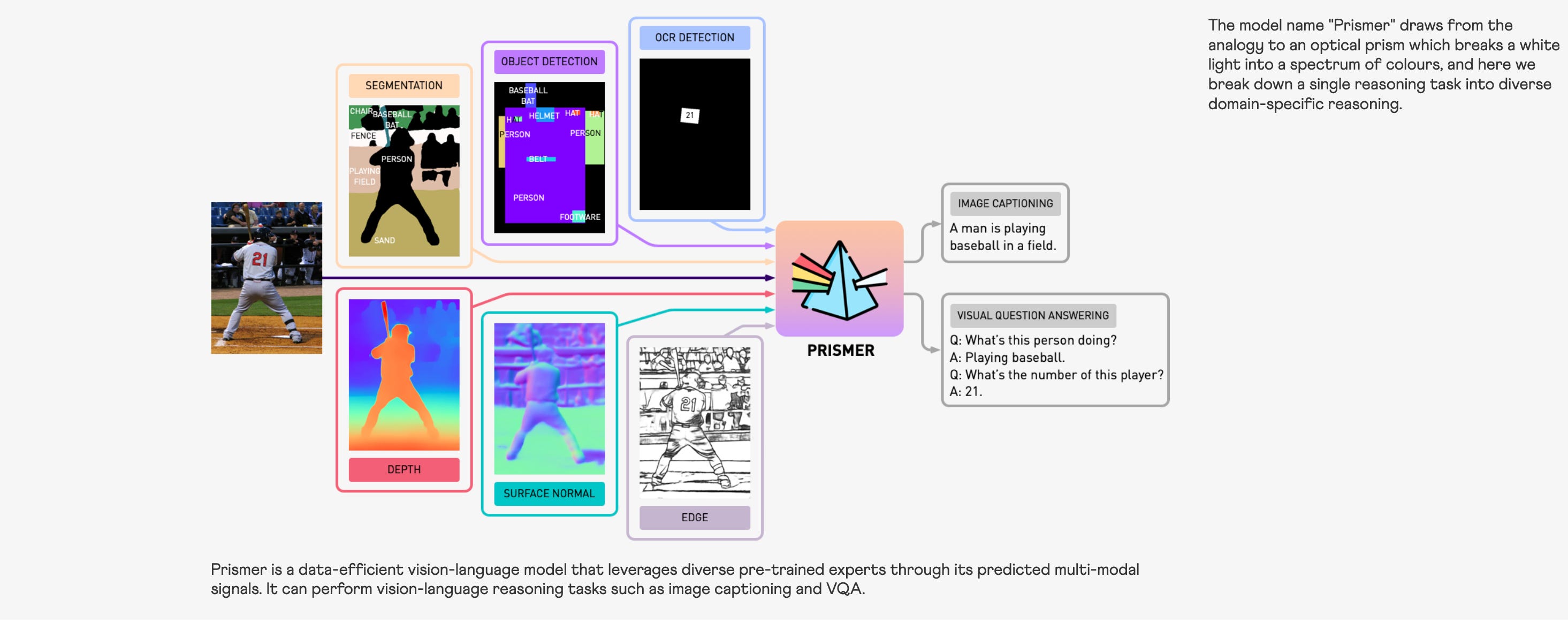
NVIDIA labs proposes an interesting Mixture of Experts Model called Prismer and in a nutshell:
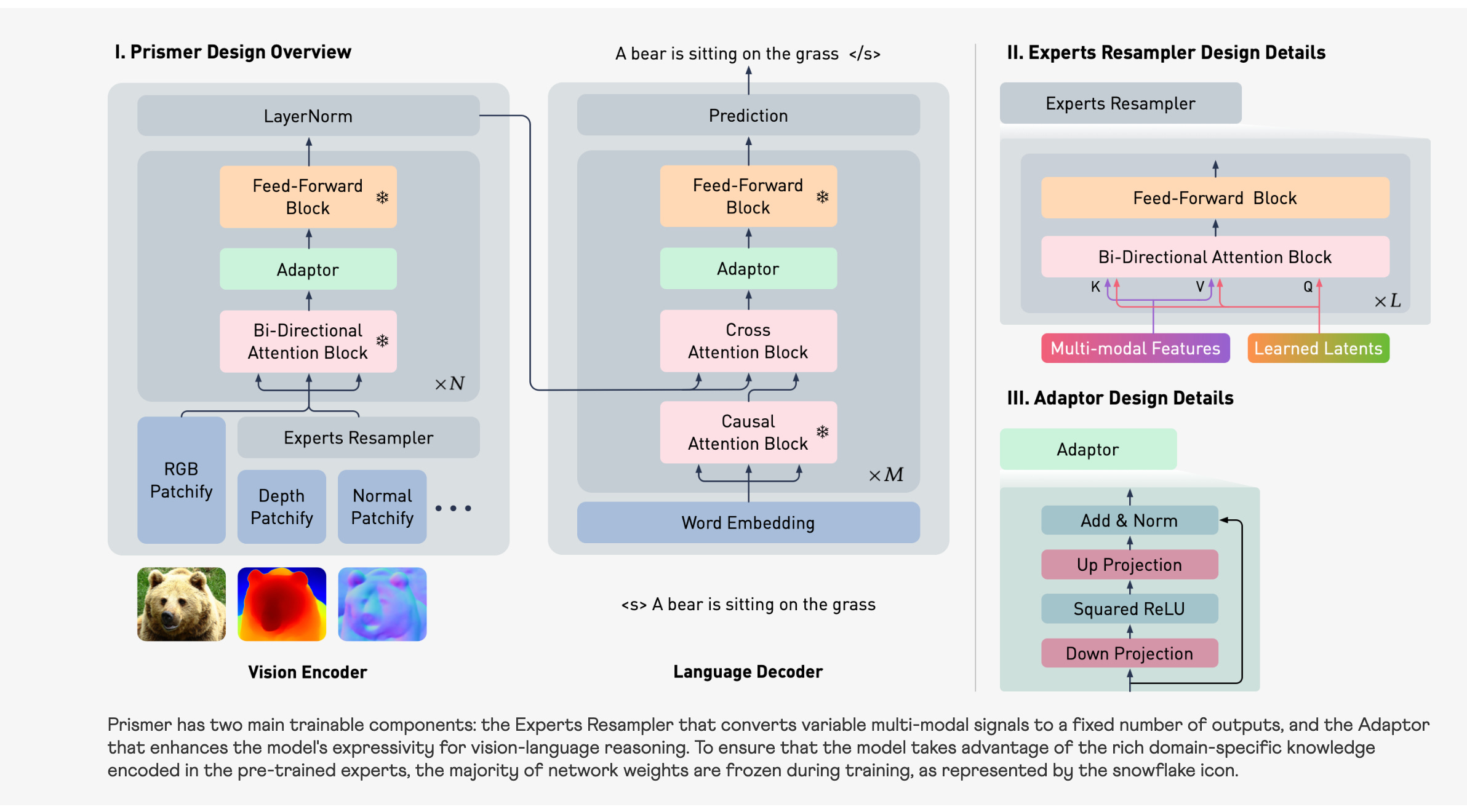
Prismer, a visually conditioned autoregressive text generation model, trained to better use diverse pre-trained domain experts for open-ended vision-language reasoning tasks. Prismer's key design elements include, i) powerful vision-only and language-only models for web-scale knowledge, and ii) modality-specific vision experts encoding multiple types of visual information, including low-level vision signals such as depth, and high-level vision signals, such as instance and semantic labels, as a form of auxiliary knowledge. All expert models are individually pre-trained and frozen, and are connected through some lightweight trainable components, that only comprise roughly 20% of total network parameters.
It is interesting that, experts themselves are individually trained and then stacked them together.
Each expert can be optimised independently for a specific task, allowing for the use of domain-specific data and architectures that would not be feasible with a single large network. This leads to improved training efficiency, as the model can focus on integrating specialised skills and domain knowledge, rather than trying to learn everything at once, making it an effective way to scale down multi-modal learning
This method is better with more experts, better experts and robust to noisy experts and outlined the following advantages:
Observation #1: More Experts, Better Performance. They observe that the performance of Prismer improves with the addition of more modality experts. This is because more experts provide a greater diversity of domain knowledge to the model. They also note that the performance of the model eventually plateaus, which suggests that additional modality experts do not provide any extra gains beyond a certain number.
Observation #2: Better Experts, Better Performance. To evaluate the impact of expert quality on Prismer's performance, they construct a corrupted depth expert by replacing a certain number of predicted depth labels with random noise sampled from a Uniform Distribution. Prismer's performance improves as the quality of the depth expert improves. This is intuitive as better experts provide more accurate domain knowledge, allowing the model to perceive more accurately.
Observation #3: Robustness to Noisy Experts. Their results also demonstrate that Prismer maintains performance even when including experts that predict noise. Interestingly, adding noise can even result in a non-trivial improvement compared to training on RGB images alone, which can be considered as a form of implicit regularisation. This property allows the model to safely include many experts without degrading the performance, even when the expert is not necessarily informative. Therefore, Prismer presents a more effective learning strategy than the standard multi-task or auxiliary learning methods, which either require exploring task relationships or designing more advanced optimisation procedures.
The paper has more details, the code(PyTorch) is also available in GitHub.

Google extends their PALM language into Palm-E through training encoders that convert a variety of inputs into the same space as the natural word token embeddings. These continuous inputs are mapped into something that resembles "words" (although they do not necessarily form discrete sets). Since both the word and image embeddings now have the same dimensionality, they can be fed into the language model. By doing so, they can extend their backbone Large Language Model(PaLM) to support a variety of modalities of inputs.

2 research firms summarized the ML Competitive machine learning in a report. It talks about various competitions like medical, NLP, reinforcement learning and talks about winning solutions. Definitely, worth a check it out especially on the tools and libraries front, you might find something that you have not seen before in your field.
Libraries
A curated list of algorithms for auditing black-box algorithms. Nowadays, many algorithms (recommendation, scoring, classification) are operated at third party providers, without users or institutions having any insights on how they operate on their data. Audit algorithms in this list thus apply to this setup, coined the "black-box" setup, where one auditor wants to get some insight on these remote algorithms.
online_conformal implements numerous algorithms which perform conformal prediction on data with arbitrary distribution shifts over time. This is the official implementation for the paper; Improved Online Conformal Prediction via Strongly Adaptive Online Learning.
OpenICL provides an easy interface for in-context learning, with many state-of-the-art retrieval and inference methods built in to facilitate systematic comparison of LMs and fast research prototyping. Users can easily incorporate different retrieval and inference methods, as well as different prompt instructions into their workflow. The paper has more details and comparison with other approaches.
tiktoken is a fast Byte pair encoding tokeniser for use with OpenAI's models. It is also used in ChatGPT/GPT-4.
OpenML is an open platform for sharing datasets, algorithms, and experiments - to learn how to learn better, together.
Codabench is a platform allowing you to flexibly specify a benchmark. First you define tasks, e.g. datasets and metrics of success, then you specify the API for submissions of code (algorithms), add some documentation pages, and [CLICK] your benchmark is created, ready to accept submissions of new algorithms. Participant results get appended to an ever-growing leaderboard.
TorchDrift is a data and concept drift library for PyTorch. It lets you monitor your PyTorch models to see if they operate within spec.