ChatGPT-OSS from OpenAI
and how this move is related to Android being open-sourced by Google

OpenAI open-sources GPT!

OpenAI's recent release of its first open-weight models since GPT-2—gpt-oss-120b and gpt-oss-20b—represents far more than a return to the company's open-source roots. This move signals a defensive strategy that mirrors Google's Android strategy, demonstrating how open-sourcing can paradoxically strengthen competitive moats while appearing to give away the crown jewels for companies.
In this article, I will draw some parallels between OpenAI's pivot to OSS and Google's Android ecosystem reveals how companies can weaponize openness to maintain long-term dominance.
After Google acquired Android, its strategy established the definitive playbook for using open source as a defensive weapon. Google open-sourced Android and the move was anything but altruistic—it was strategic defensive play designed to prevent platform lock-in by competitors. The core was that by commoditizing the mobile operating system layer, Google could ensure its services remained accessible across the entire mobile ecosystem, regardless of hardware manufacturer.
Android's open-source nature created what appeared to be a fragmented market with multiple hardware vendors—Samsung, LG, HTC, and others—all competing on the same platform. However, one thing was same with this level of fragmentation: every Android device became a Google services delivery vehicle. While hardware manufacturers competed on margins, Google maintained control over the profitable layer—search, advertising and later other services. The company traded short-term licensing revenue for long-term platform dominance, ensuring that even as the mobile market exploded, Google's core business remained protected and its distribution of services are not disturbed in a fragmented HW vendors space.
The defensibility wasn't just about market access or distribution; it was about preventing competitive platform lock-in. Had Apple's iOS or Microsoft's Windows Mobile achieved total dominance, Google could have found itself locked out of mobile entirely, with competitors controlling the gateway to billions of users. Android's open architecture made such exclusion impossible while creating powerful network effects that grew stronger with each new device and developer.


Android actually won against iOS in the world with a large market share(Android: 72.13% and iOS: 27.48%) and competed well within USA(58.68% iOS and 41.03% Android).
OpenAI's Strategic Parallel
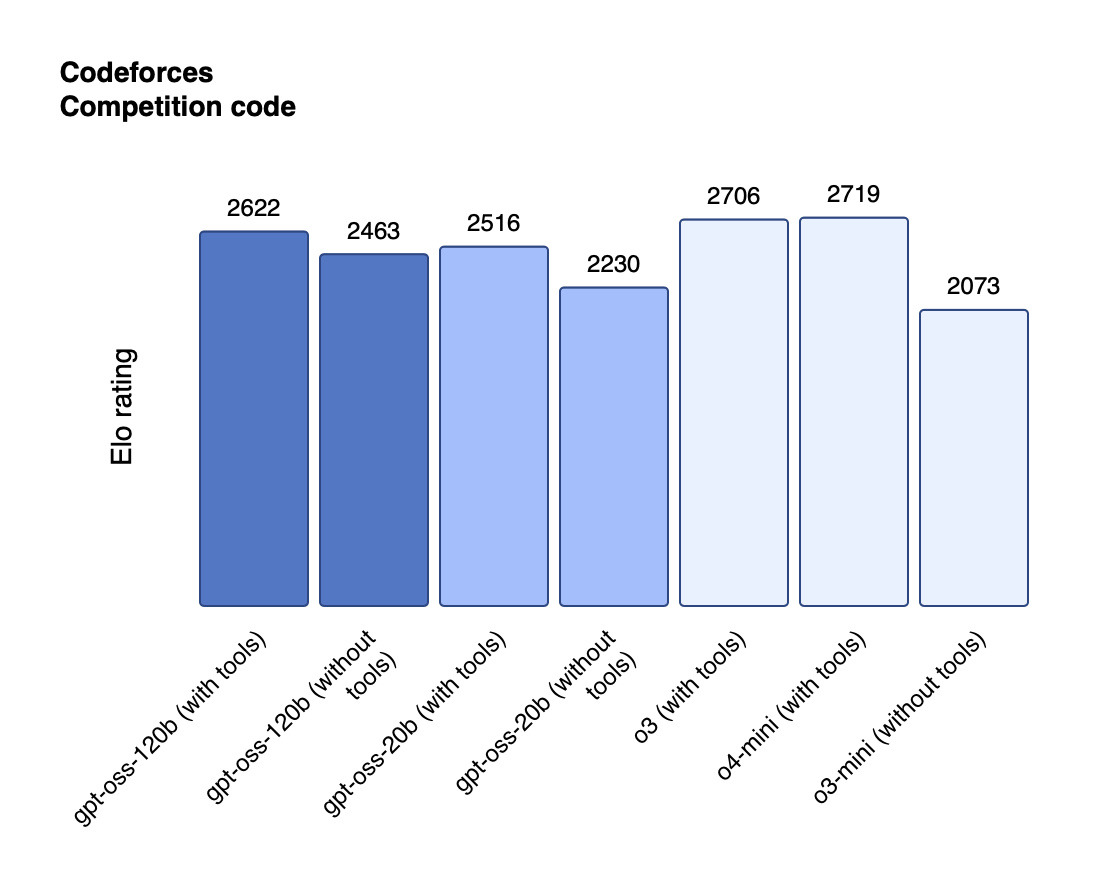
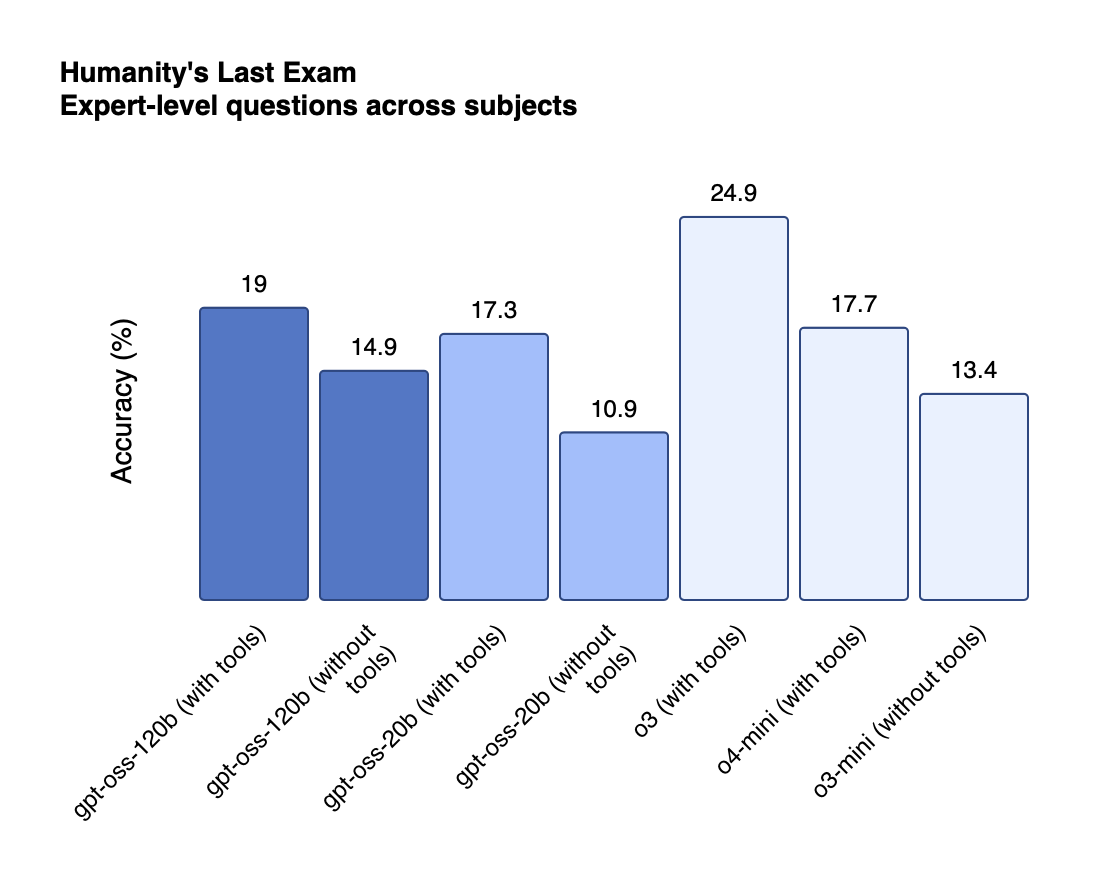
OpenAI's open-weight model release follows the same strategic logic, adapted for the AI era. Facing mounting pressure from competitors like DeepSeek, Alibaba's Qwen, and other open-source models that deliver "roughly 90% of the performance at a mere 10% of the cost", OpenAI found itself in a position eerily similar to Google in 2005—potentially being outplayed by more open alternatives.
The strategic calculus is clear: rather than lose market share to open-source competitors, OpenAI is commoditizing the foundation model layer while maintaining superiority in the premium tier. The gpt-oss models aren't OpenAI's best technology—that remains with GPT-5 and the closed-source premium offerings. Instead, they're strategic weapons designed to prevent the open-source ecosystem from entirely bypassing OpenAI's influence and defend OpenAI against such pressures.
This approach serves multiple defensive purposes simultaneously. First, it counters the narrative that OpenAI has abandoned its open-source roots, addressing criticism from who accused the company of betraying its founding principles. Second, it provides a competitive alternative to increasingly sophisticated other competitor models.
Most importantly, the open-weight models function as an ecosystem builder. Just as Android attracted developers to Google's platform, gpt-oss models draw AI researchers and developers into OpenAI's orbit, creating network effects around the company's tools, frameworks, and cloud infrastructure. I will expand this a bit more later but especially fine-tuning will become more important to build specialized models, this section might be more and more important as it will allow developers to use a particular operating system to build their applications.
Closed and Open as Complementary Weapons
Both strategies lies in how they balance closed and open components to maximize strategic advantage. Google didn't open-source everything about Android—Google Services, the most valuable components of the ecosystem, remained proprietary. This allowed Google to maintain control over critical functionality while benefiting from the innovation and adoption that open source enables.
OpenAI employs a similar dual strategy architecture. The open-weight gpt-oss models provide a foundation that developers can build upon, but they're explicitly positioned as complementary to OpenAI's premium closed-source offerings. The architecture also includes hybrid capabilities—if the open model encounters a task beyond its capabilities, it can seamlessly call OpenAI's closed-source models in the cloud where the better/more capable model can be used and marketed to the user if the OSS model cannot respond to the task at hand.
This creates a good funnel effect: developers start with the free open models, become embedded in OpenAI's ecosystem, and naturally graduate to premium services as their needs scale or capabilities that lie beyond OSS models. The open models serve as both competitive defense and customer acquisition vehicle, similar to how free Android devices drove users toward Google's profitable services.
Network Effects and Platform Lock-in
Both strategies leverage network effects to create sustainable competitive advantages. Android's success created a virtuous cycle: more devices meant more users, which attracted more developers, which created better applications, which attracted more users. The scale advantages became self-reinforcing, making it increasingly difficult for competitors to challenge Google's position.
OpenAI's open-weight strategy aims to replicate these dynamics in AI. By providing high-quality foundation models under permissive Apache 2.0 licensing, OpenAI encourages widespread adoption and customization. As developers build applications, fine-tune models, and create derivative works, they become increasingly embedded in OpenAI's technical ecosystem.
The network effects extend beyond direct usage. Open models enable OpenAI to benefit from crowdsourced research and development. The global community of developers becomes an unpaid R&D workforce, discovering new applications, identifying limitations, and contributing improvements that OpenAI can incorporate into future releases. This approach provides innovation velocity that even well-funded internal teams struggle to match.
The Strategic Duality
Both strategies lies in their simultaneous offensive and defensive capabilities. Defensively, Android protected Google from mobile platform exclusion while OpenAI's open models protect against commoditization by pure open-source alternatives. Offensively, both strategies actively undermine competitors' business models.
Android's open nature made it difficult for competitors to charge premium prices for mobile operating systems, effectively commoditizing Microsoft and other proprietary mobile platforms. Similarly, OpenAI's open-weight models directly challenge the business models of competitors like Anthropic and other AI companies that rely primarily on API access revenue.
The attack mechanism is particularly sophisticated because it converts competitors' advantages into liabilities. Companies that built their entire business around selling access to AI models suddenly face competition from free, high-quality alternatives. This would also prevent and make the new entry to be harder while OpenAI does not lose its competitive moat through its premium offering. Further, OpenAI—with its diversified revenue streams including enterprise contracts, cloud services, and premium features—can absorb the short-term revenue impact while competitors struggle with their core business model disruption.
Strengthening Through Apparent Weakness
Both strategies demonstrate the moat paradox: sometimes the best way to build defensibility is to appear to give it away. By open-sourcing core technology, both Google and OpenAI created deeper, more sustainable competitive advantages than traditional proprietary approaches could provide.
The key insight is that technology itself is not the ultimate moat. True defensibility comes from network effects, data advantages, talent concentration, and ecosystem lock-in. Open source can actually strengthen these deeper moats by accelerating adoption, creating developer loyalty, and establishing technology standards that competitors must follow rather than lead.
Google's Android strategy proved that controlling the platform matters more than controlling the code. OpenAI's approach suggests that in AI, the training infrastructure, and the path to premium capabilities matters more than protecting individual model weights.

Google open sourced a new Gemma 3 270M model, which is a family of open-source models from Google. The main model is a compact model engineered for hyper-efficient AI applications, mainly mobile and applications where power consumption is as important as model accuracy.
Further, the larger Gemma collection is enhanced with other more efficient models, including Gemma 3, Gemma 3 QAT (quantization-aware training), and Gemma 3n—a mobile-oriented, real-time multimodal AI model tailored for edge deployments rather than server based applications.
For LLMs, generally tendency to build and employ ever-larger models under the notion that size equates to capability. Therefore, the larger the model, the better model is. However, there is also an important dimension in LLM application and deployment where efficiency matters a lot, especially in mobile and edge deployments. Specialized, smaller models like Gemma 3 270M offer a leaner, cost-effective alternative, especially for highly defined tasks such as text classification or structured data extraction for applications that do not require a lot of capabilities that large models offer while still can do an excellent job on these applications that are deployed in mobile and edge.
Gemma 3 270M is designed as a fine-tuning-friendly, compact foundation model with a parameter count of 270 million. It is intentionally positioned as the starting point for building task-specific AI agents—so-called “small, specialized models”—each narrowly focused and highly optimized for its domain. The underlying philosophy is to enable developers to create modular AI systems, each with targeted abilities, rather than burdening a single, large model with many disparate tasks.
It is good for:
Fast, accurate text classification
Data extraction from documents
Instruction-following and text structuring tasks
Multimodal applications when paired with additional assets (e.g., for mobile or edge deployment)
Gemma 3 270M: Technical Overview
Parameter Count: 270 million—this makes the model light compared to mainstream large language models (LLMs) that often contain billions or tens of billions of parameters. Compare this with GPT-OSS-120B from OpenAI which has about 117 Billion parameters.
Fine-Tuning Paradigm Shift
Gemma 3 270M is specifically designed for rapid, efficient task-specific fine-tuning. Its size and robust pre-training make it ideal for organizations aiming to deploy multiple narrow models—sometimes called “expert models”—each optimized for a particular workflow.
This approach is consistent with growing trends in AI, where “model specialization” outperforms attempts to cover all needs with a single, general-purpose foundation model.
Instruction Structuring and Out-of-Box Quality
Larger models are often cumbersome and require extensive re-training or adaptation to follow instructions accurately. In contrast, Gemma 3 270M offers high-fidelity instruction-following without extra overhead. The architecture incorporates prior learnings from instruction tuning, reinforcement with human feedback, and possibly synthetic data training strategies, ensuring reliable zero-shot and few-shot performance for common tasks.
Efficiency and Cost-Effectiveness
Smaller parameter count translates into significantly lower compute, memory, and energy requirements—crucial for both enterprise-scale deployments (where inference costs scale rapidly with usage) and on-device AI scenarios.
Gemma 3 270M’s architecture likely employs advanced quantization and pruning techniques for further efficiency, although the article references QAT (in Gemma 3 QAT) but doesn’t specify whether this model is pre-quantized.
Edge and Mobile Compatibility Through Shared Architecture
By building on the same architecture as Gemma 3 and Gemma 3n, Google ensures horizontal portability—models can be trained and then later adapted for smaller, even mobile-specific variants.
The efficient transformer backbone, fused attention mechanisms, and potential optimizations for ARM or edge hardware mean developers can expect real-time inference, even on non-datacenter hardware.
The models are available in HuggingFace, you can also experiment and try out the models in the Google Vertex as well. Fine-tuning on Gemma models is also available as a notebook.
Libraries

POML (Prompt Orchestration Markup Language) is a novel markup language designed to bring structure, maintainability, and versatility to advanced prompt engineering for Large Language Models (LLMs). It addresses common challenges in prompt development, such as lack of structure, complex data integration, format sensitivity, and inadequate tooling. POML provides a systematic way to organize prompt components, integrate diverse data types seamlessly, and manage presentation variations, empowering developers to create more sophisticated and reliable LLM applications.

LangExtract is a Python library that uses LLMs to extract structured information from unstructured text documents based on user-defined instructions. It processes materials such as clinical notes or reports, identifying and organizing key details while ensuring the extracted data corresponds to the source text.

Precise Source Grounding: Maps every extraction to its exact location in the source text, enabling visual highlighting for easy traceability and verification.
Reliable Structured Outputs: Enforces a consistent output schema based on your few-shot examples, leveraging controlled generation in supported models like Gemini to guarantee robust, structured results.
Optimized for Long Documents: Overcomes the "needle-in-a-haystack" challenge of large document extraction by using an optimized strategy of text chunking, parallel processing, and multiple passes for higher recall.
Interactive Visualization: Instantly generates a self-contained, interactive HTML file to visualize and review thousands of extracted entities in their original context.
Flexible LLM Support: Supports your preferred models, from cloud-based LLMs like the Google Gemini family to local open-source models via the built-in Ollama interface.
Adaptable to Any Domain: Define extraction tasks for any domain using just a few examples. LangExtract adapts to your needs without requiring any model fine-tuning.
Leverages LLM World Knowledge: Utilize precise prompt wording and few-shot examples to influence how the extraction task may utilize LLM knowledge. The accuracy of any inferred information and its adherence to the task specification are contingent upon the selected LLM, the complexity of the task, the clarity of the prompt instructions, and the nature of the prompt examples.
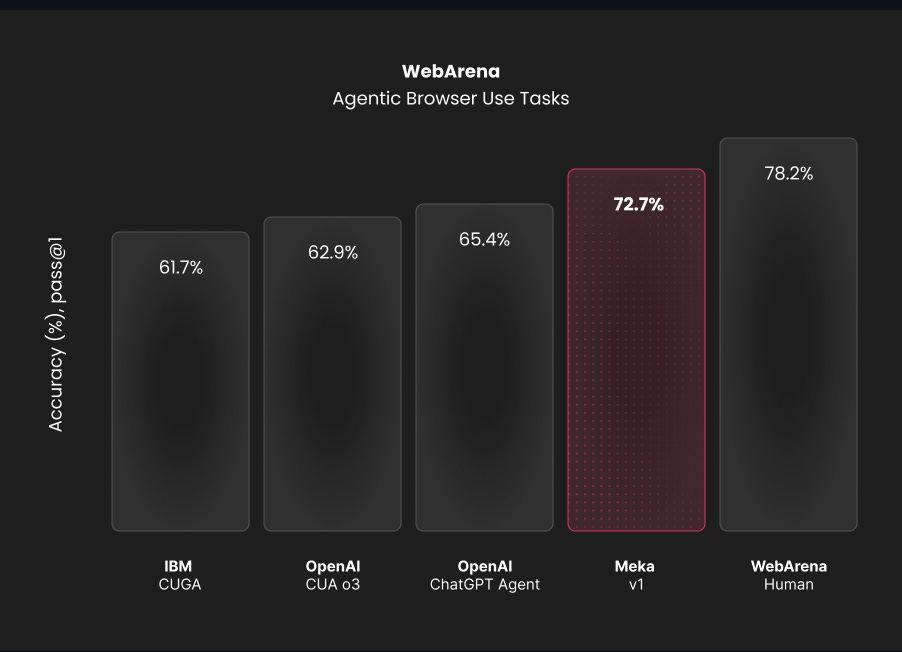
Meka Agent is an open-source, autonomous computer-using agent that delivers state-of-the-art browsing capabilities. The agent works and acts in the same way humans do, by purely using vision as its eyes and acting within a full computer context.
It is designed as a simple, extensible, and customizable framework, allowing flexibility in the choice of models, tools, and infrastructure providers.
The agent primarily focuses on web browsing today, and achieves state-of-the-art benchmark results in the WebArena Benchmark (72.7%).

TraceRoot is an open-source debugging platform that helps engineers fix production issues 10x faster by combining structured traces, logs, and source code context with AI-powered analysis.
Below The Fold

Optician Sans is a free typeface based on the 10 historical optotype letters seen on millions of eye charts around the world, finalising the work that was started decades ago.
The universal optometrist eye charts have been around for decades and seen by millions of people worldwide. The first standardised chart was created by Hermann Snellen in the Netherlands in 1862, before Louise Sloan designed a new set in 1959. These letters make up the now universal chart for testing visual acuity, also known as the LogMAR chart, which was developed by National Vision Research Institute of Australia. But ever since 1959, they have consisted of only 10 letters.
Optician Sans is a fully functional typeface based on the historical optotype letters, including numbers and special characters.
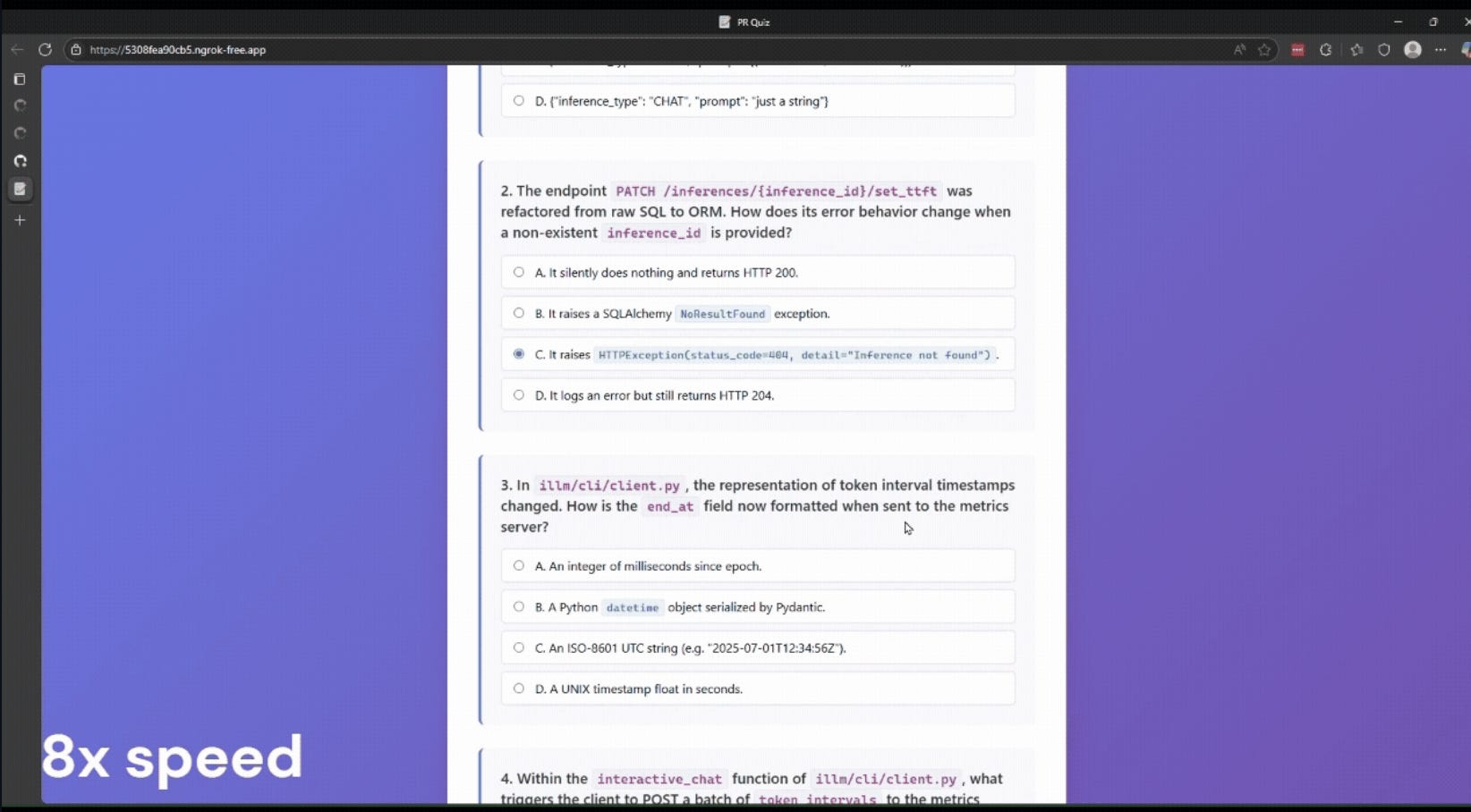
PR Quiz is a GitHub Action that uses AI to generate a quiz based on a pull request. It can help you, the human reviewer, test your understanding of your AI Agent's code. (And block you from deploying code you don't understand!)

copyparty turns almost any device into a file server with resumable uploads/downloads using any web browser
Kitten TTS 😻 is an open-source realistic text-to-speech model with just 15 million parameters, designed for lightweight deployment and high-quality voice synthesis.