

Batch Calibration for LLMs
Flash Decoding, MiniGPT-v2 is now out!

Libraries

This repository contains the official implementation of "Separate Anything You Describe".
AudioSep, a foundation model for open-domain sound separation with natural language queries. AudioSep demonstrates strong separation performance and impressive zero-shot generalization ability on numerous tasks such as audio event separation, musical instrument separation, and speech enhancement. Check the separated audio examples in the Demo Page!

tinyvector - the tiny, least-dumb, speedy vector embedding database.
Tiny: It's in the name. It's just a Flask server, SQLite DB, and Numpy indexes. Extremely easy to customize, under 500 lines of code.
Fast: Tinyvector wlll have comparable speed to advanced vector databases when it comes to speed on small to medium datasets.
Vertically Scales: Tinyvector stores all indexes in memory for fast querying. Very easy to scale up to 100 million+ vector dimensions without issue.

CodeT5+ is a new family of open code large language models with an encoder-decoder architecture that can flexibly operate in different modes (i.e. encoder-only, decoder-only, and encoder-decoder) to support a wide range of code understanding and generation tasks.

To train CodeT5+, we introduce a diverse set of pretraining tasks including span denoising, causal language modeling, contrastive learning, and text-code matching to learn rich representations from both unimodal code data and bimodal code-text data. Additionally, to efficiently scale up the model, we propose a simple yet effective compute-efficient pretraining method to initialize our model with frozen off-the-shelf LLMs such as CodeGen. Furthermore, we explore instruction tuning to align the model with natural language instructions following Code Alpaca. See the below overview of CodeT5+.

AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
AutoGen enables building next-gen LLM applications based on multi-agent conversations with minimal effort. It simplifies the orchestration, automation, and optimization of a complex LLM workflow. It maximizes the performance of LLM models and overcomes their weaknesses.
It supports diverse conversation patterns for complex workflows. With customizable and conversable agents, developers can use AutoGen to build a wide range of conversation patterns concerning conversation autonomy, the number of agents, and agent conversation topology.
It provides a collection of working systems with different complexities. These systems span a wide range of applications from various domains and complexities. This demonstrates how AutoGen can easily support diverse conversation patterns.
AutoGen provides a drop-in replacement of
openai.Completionoropenai.ChatCompletionas an enhanced inference API. It allows easy performance tuning, utilities like API unification and caching, and advanced usage patterns, such as error handling, multi-config inference, context programming, etc.
QLoRA is an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters (LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) Double Quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) Paged Optimizers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. We release all of our models and code, including CUDA kernels for 4-bit training.
The choice of how to encode positional information for transformers has been one of the key components of LLM architectures. An area that has been interesting to us and others in the community recently is whether LLMs can be extended to longer contexts.
AbacusAI have conducted a range of experiments with different schemes for extending context length capabilities of Llama, which has been pretrained on 2048 context length with the RoPE (Rotary Position Embedding) encoding. This is a repository where they share some of the results as well as the training and evaluation scripts in the hope that it will be useful to the community. For their best performing models - linear scaling with IFT at scales 4 and 16 - they are also sharing the weights in case others wish to use them, or to conduct their own tests. They believe the scale 16 model should perform well on real world tasks up to 16k context lengths, and potentially even up to about 20-24k context lengths.
Articles
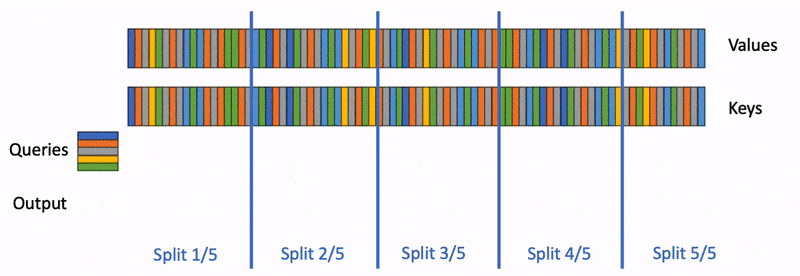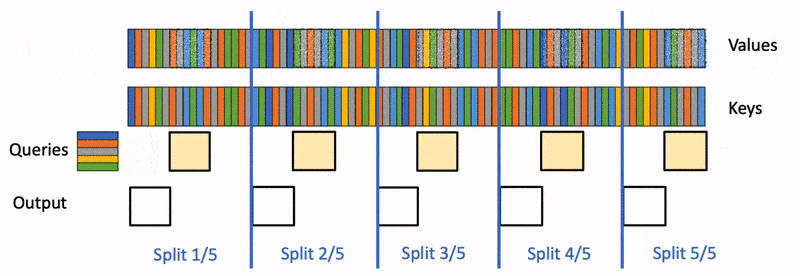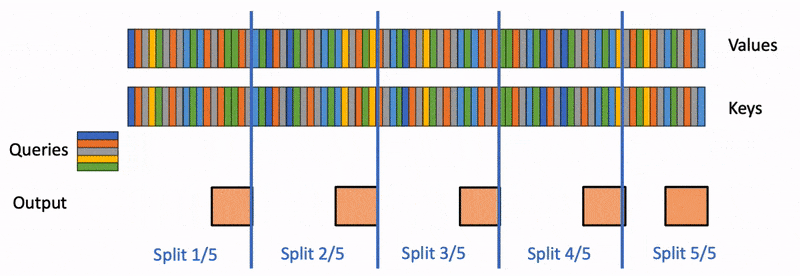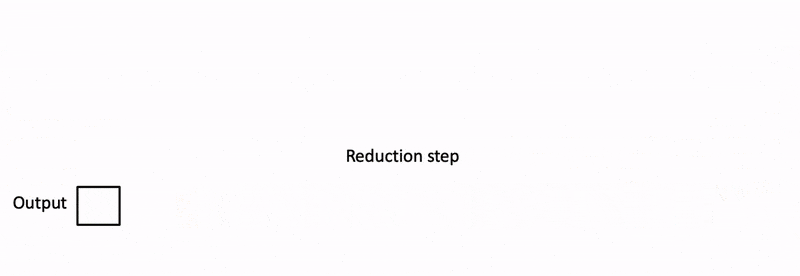
PyTorch team wrote a blog post called "Flash-Decoding" that aims to significantly speed up the inference process for Large Language Models (LLMs), such as ChatGPT or Llama. LLMs are powerful but expensive to run, and generating responses or code auto-completion can quickly accumulate costs, especially when serving many users. Flash-Decoding focuses on the attention mechanism, a critical part of LLM inference.
In LLM decoding, tokens are generated one at a time, and full sentence generation requires multiple passes through the model. Attention is a computationally expensive operation, particularly when dealing with long contexts or batch processing. Flash-Decoding aims to optimize this attention step during decoding to make it more efficient.
Use cases of Flash Decoding are over the other types of decoding mechanisms:
Attention Optimization: Attention, the process that calculates the relevance of previous tokens for generating a new token, can become a bottleneck during decoding, especially for long contexts.
FlashAttention: FlashAttention was introduced earlier and optimized attention for training but didn't work efficiently during inference, where query length is typically 1. This approach suffered from underutilizing the GPU resources.
Flash-Decoding: Flash-Decoding builds upon FlashAttention but introduces a new parallelization dimension, keys/values sequence length, to fully utilize the GPU. It splits keys and values into smaller chunks and computes attention in parallel, resulting in better GPU utilization.
Benefits: Flash-Decoding delivers significant speedups in decoding speed, up to 8x faster for very long sequences, and it scales better compared to alternative methods.
Use Cases: Flash-Decoding can be applied to various LLMs and is particularly beneficial for long context sequences.
Availability: Flash-Decoding is available in the FlashAttention package and through xFormers, making it accessible for developers to implement in their LLM applications.

Google wrote about batch calibration for In Context learning and prompt learning in a detailed blog post. You might ask what is in-context learning?
In-context learning (ICL) is a technique for training large language models (LLMs) by providing them with a few examples and asking them to learn from them. In Context learning is not itself enough. We also need to have calibration which is the process of adjusting the output of a model to make it more accurate. It is important to calibrate LLMs because they can be biased and produce inaccurate outputs, especially when they are used with ICL.
However, existing calibration methods for LLMs have a number of limitations. They are often task-specific, requiring labeled data to train. They can also be sensitive to the design of the prompt.
Google introduces a new Batch calibration (BC) is a new calibration method that addresses these limitations. BC is zero-shot, meaning that it does not require any labeled data to train. It is also inference-only, meaning that it can be used to calibrate LLMs after they have been trained. BC is also robust to prompt design choices, making it more reliable than previous calibration methods.
BC works by calibrating the outputs of a model based on the outputs of the model on a batch of examples. BC uses a technique called "distribution matching" to adjust the output of the model to match the distribution of the desired output.
BC has been shown to outperform previous calibration methods on a variety of natural language and image classification tasks. For example, BC improved the accuracy of a GPT-3 model on a natural language inference task by 10%. BC also improved the accuracy of a CLIP model on an image classification task by 5%.
The advantages of this calibration method over others are in the following:
BC is zero-shot, meaning that it does not require any labeled data to train.
BC is inference-only, meaning that it can be used to calibrate LLMs after they have been trained.
BC is robust to prompt design choices, making it more reliable than previous calibration methods.
BC has been shown to outperform previous calibration methods on a variety of natural language and image classification tasks.
Papers

Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, researchers from Meta and King Abdullah University of Science and Technology target to build a unified interface for completing many vision-language tasks including image description, visual question answering, and visual grounding, among others. The challenge for achieving this is to use a single model for performing diverse vision-language tasks effectively with simple multi-modal instructions. To address this issue, researchers introduce MiniGPT-v2, a model can be treated a unified interface for better handling various vision-language tasks. We propose using unique identifiers for different tasks when training the model. These identifiers enable our model to distinguish each task instruction effortlessly and also improve the model learning efficiency for each task. After our three-stage training, the experimental results show that MiniGPT-v2 achieves strong performance on many visual question answering and visual grounding benchmarks compared to other vision-language generalist models.

In the field of recommender systems, shallow autoencoders have recently gained significant attention. One of the most highly acclaimed shallow autoencoders is EASE, favored for its competitive recommendation accuracy and simultaneous simplicity. However, the poor scalability of EASE (both in time and especially in memory) severely restricts its use in production environments with vast item sets.
In this paper, we propose a hyperefficient factorization technique for sparse approximate inversion of the data-Gram matrix used in EASE. The resulting autoencoder, SANSA, is an end-to-end sparse solution with prescribable density and almost arbitrarily low memory requirements (even for training). As such, SANSA allows us to effortlessly scale the concept of EASE to millions of items and beyond.
Videos
From Machine Learning to Autonomous Intelligence talk from Yann Lacuna shows a number of different applications of the recent developments in deep learning, mainly in the LLM and other types of generative models:
The slides are here.