Attention Structures with Associative Recall in Transformers
Zoology, Striped Hyena, vLLM, Alpaca

Articles

Stanford's Hazy Research wrote a post a while back. It compares attention structures with newer efficient and possibly attention-free alternatives, particularly focusing on associative recall(AR) capabilities in the comparison.
There has been a lot of interest in attention-free, efficient LLM architectures that aim to challenge the dominance of Transformer-based models as attention is really expensive and hard to scale due to how much compute that it requires for scaling. These new architectures include various Approximate Attention Methods(AAN), S4, Liquid S4, MEGA, GSS, H3, BIGS, Hyena, RWKV, RetNet, Monarch Mixer, Mamba, etc. While recent work suggested some of these architectures could match attention in benchmark quality, this post aims to investigate their performance more thoroughly, particularly focusing on a class of sub-quadratic Transformer alternatives called "gated-convolutions" (e.g., Hyena, H3, and RWKV).
The blog post reveals a significant performance gap in associative recall (AR) - the ability to recall information previously mentioned in the prompt. This capability has substantial implications for in-context learning and practical applications and how LLMs are being used in the real-world applications.
The evaluation setting uses pretrained 17 language models from scratch spanning four parameter scales (70M, 150M, 360M, and 1.4Bn) across various architectures to study the scaling properties of the various model architectures as well:
H3: Uses a short convolution followed by a long convolution, sandwiched by element-wise gating.
Hyena: Similar to H3 but differs in the parametrization and placement of convolutions.
RWKV: Often described as an RNN but can be rewritten as a gated convolution, differing in parametrization for convolution filters, ordering of gating, convolutions, and projections.
Pure long convolutions (S4-like): Uses a global/long convolution without gating.
Llama-style Transformers: Modern Transformer baseline with rotary embeddings.
All models were trained on uniform infrastructure and data (The Pile for 10B tokens, 50B for 1.4Bn parameter models) using the EleutherAI GPT-NeoX codebase.
They have found a consistent perplexity gap between state-of-the-art attention-free models and Transformer based architectures(attention-based). More significantly, they have identified that a single issue was responsible for more than 82% of this gap: poor performance on tokens requiring associative recall. Remarkably, a 1.4 billion parameter Hyena model underperformed a 70 million parameter attention model by over a perplexity point on the AR slice.
To measure AR capability in real LLMs, the post proposes a simple proxy: evaluating the model's perplexity on the subset of next-token-predictions that form completions to repeated bigrams, termed "AR Hits". For example, in phrases like "crosscut complex" and "Maison Bergey," the second occurrences of "complex" and "Bergey" are considered AR Hits because they can be predicted by recalling the prior occurrences of these bigrams in the context.
Critically, the researchers distinguished between bigrams that might be memorized during training (like "Barack Obama") and those that require genuine in-context recall. When plotting perplexity against the frequency of bigrams in training data, they observed a pattern: for AR hits appearing infrequently in training data, there was a large gap between gated convolution models and attention models. On other hand, tokens and frequently appearing AR hits, there was virtually no gap between the models.
This finding suggested that in-context recall is the fundamental issue separating gated convolution models from attention-based ones and why attention based models are superior for applications that require in-content recall in the model properties. The researchers further confirmed this by comparing RWKV-Raven 7B and Llama 2 7B, finding that the gap persists at larger scales and increases as models need to conduct more recalls per input sequence.
When examining the AR capabilities though, the evaluation setup had a big problem: gated convolutions could solve synthetic AR tasks perfectly in previous work, yet showed significant gaps on real-world language data. To resolve this gap in the evaluation methods, they developed a new synthetic task called Multiple Query Associative Recall (MQAR).
The key insight was that prior synthetic formulations assumed one query per input at a fixed position, with tokens from a small vocabulary (less than model dimension). However, real language modeling often requires performing multiple recalls at varying positions with tokens from large vocabularies (larger than model dimension).
MQAR better reflects these real-world demands by:
Having multiple keys that need to be recalled in a single sequence
Placing keys at random positions in the sequence
Using a larger vocabulary size
Through theoretical analysis and experiments, post mentions that:
Even though gated convolutions are sub-quadratic in sequence length, the architecture requires larger model widths (dimensionality, hidden size) than attention to solve MQAR effectively.
They validated these theoretical results by constructing BaseConv, a canonical, simplified gated convolution model that can provably simulate all other models built from gating and convolution primitives including H3, Hyena, and RWKV. The experiments among these architectures, they observed that model dimension needs to grow with sequence length to solve MQAR as well as attention does.
While all the architectures can solve the AR task, the scaling required to do so becomes increasingly problematic with longer sequences, negating some of the efficiency benefits of gated convolutions. Interestingly, another way to look at this is that transformer based or attention based model architectures might be more efficient on learning for a given/finite sequence length than the ones that are attention-free.
After empirical results, the post also tries to build a hypothesis on a theoretical ground to explain the results, especially on scaling properties of attention-free methods. In order to do so, they manually set weights of gated convolution models to solve associative recall and demonstrated why poor scaling emerges from these architectures.
They define a minimal representation of gated convolution called BaseConv, which can simulate all other architectures built from gating and convolution primitives. In code, BaseConv is elegantly simple:
v = conv(u) // convolution
w = linear(u) // projection
y = v * w // gatingA convolution between two discrete sequences can be viewed as a polynomial operation
Gating (Hadamard product) between two sequences can also be viewed as a polynomial operation
Therefore, an overall gated convolution model can be analyzed as a complex polynomial
In here, main idea is to compare operation in the attention function and operation in the BaseConv.

Both attention and convolutions take input sequences of embeddings and output sequences of the same shape by applying a linear transform that "mixes" the embeddings together. However, they differ from one main dimension is that:
In Attention: The mixing matrix is a function of the input
In Gated Convolutions: The mixing matrix is defined by model parameters and is NOT a function of the input
How Attention solves MQAR
Attention can solve MQAR using two layers:

Layer 1 (Shift-by-one): Shifts each key by one position so the output embedding contains both the MQAR key and value (e.g., by storing the MQAR key in the first dimensions and the MQAR value in the rest).

Layer 2 (Lookup): Performs long-range lookups using the MQAR key part of the embedding as attention keys and the MQAR value part as attention queries and values. This makes it easy to find matching MQAR keys by computing pairwise similarity of attention query and key embeddings.

Crucially, attention can solve this task with model dimension independent of sequence length (it just needs to be large enough to store two token representations).
How Gated Convolution solves MQAR
In contrast, gated convolutions require more complex solutions that scale with sequence length. Their two-layer solution works as follows:

Layer 1 (Finding Matching MQAR Keys): Uses convolution and gating to compare each token to all other tokens to find matching MQAR keys.
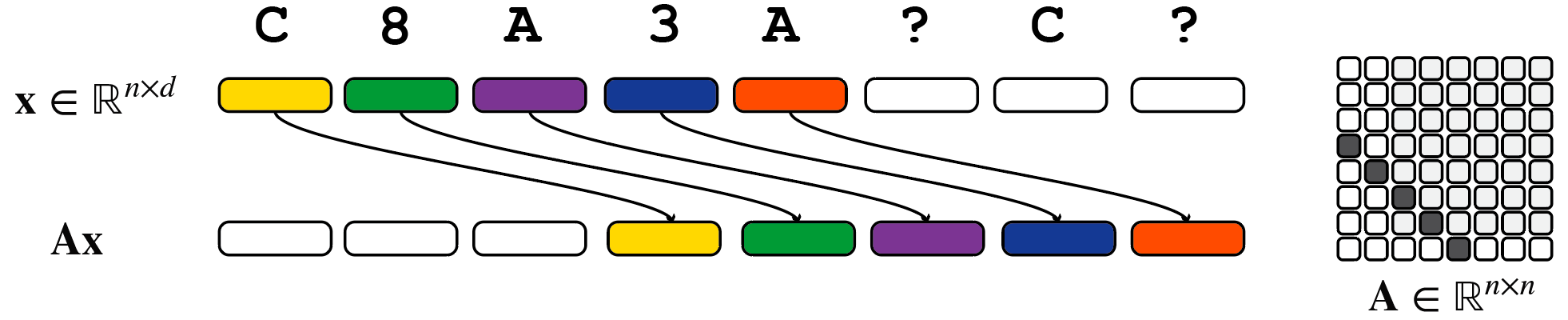
Layer 2 (Outputting MQAR Values): Uses the matches identified in the first layer to output the appropriate MQAR values.


In the literature, an architecture's efficiency is typically measured in terms of the asymptotic cost of a layer. If there's one takeaway lesson from our work, it's this: taken alone, the complexity of a layer is an inadequate measure of efficiency
In here, the finding is that both the evaluation method and how the model architecture responds to scaling need to be considered when we measure efficiency of model architecture.
What if we measured an architecture's efficiency in terms of the FLOPs required to solve a specific task, instead of the FLOPs required per layer?
In order to solve that, they come up with a new testbed for this synthetics called “Zoology” to measure efficiency.
Libraries

Zoology provides machine learning researchers with a simple playground for understanding and testing language model architectures on synthetic tasks. This repository can be used to reproduce the results in our paper Zoology: Measuring and Improving Recall in Efficient Language Models. See the section on reproducing paper experiments for details.

Mega: Moving Average Equipped Gated Attention is the PyTorch implementation of the Mega paper.

StripedHyena is the first alternative model architecture competitive with the best open-source Transformersof similar sizes in short and long-context evaluations.
StripedHyena is a deep signal processing, hybrid architecture composed of rotary (grouped) attention and gated convolutions arranged in Hyena blocks, with improved scaling over decoder-only Transformers. StripedHyena is designed to leverage the specialization of each of its layer classes, with Hyena layers implementing the bulk of the computation rjequired for sequence processing and attention layers supplementing the ability to perform targeted pattern recall.
Efficient autoregressive generation via a recurrent mode (>500k generation with a single 80GB GPU)
Low latency, faster decoding and higher throughput than Transformers.
Significantly faster training and finetuning at long context (>3x at 131k)
Improved scaling laws over state-of-the-art architectures (e.g., Transformer++) on both natural language and biological sequences.
Robust to training beyond the compute-optimal frontier e.g., training way beyond Chinchilla-optimal token amounts

👾 Letta is an open source framework for building stateful agents with advanced reasoning capabilities and transparent long-term memory. The Letta framework is white box and model-agnostic.

vLLM is a fast and easy-to-use library for LLM inference and serving.
vLLM is fast with:
State-of-the-art serving throughput
Efficient management of attention key and value memory with PagedAttention
Continuous batching of incoming requests
Fast model execution with CUDA/HIP graph
Optimized CUDA kernels, including integration with FlashAttention and FlashInfer.
Speculative decoding
Chunked prefill

BAML is a simple prompting language for building reliable AI workflows and agents.
BAML makes prompt engineering easy by turning it into schema engineering -- where you mostly focus on the models of your prompt -- to get more reliable outputs. You don't need to write your whole app in BAML, only the prompts! You can wire-up your LLM Functions in any language of your choice! See our quickstarts for Python, TypeScript, Ruby and Go, and more.

Guidance is an efficient programming paradigm for steering language models. With Guidance, you can control how output is structured and get high-quality output for your use case—while reducing latency and cost vs. conventional prompting or fine-tuning. It allows users to constrain generation (e.g. with regex and CFGs) as well as to interleave control (conditionals, loops, tool use) and generation seamlessly.

Stanford Alpaca project aims to build and share an instruction-following LLaMA model. The repo contains:
The 52K data used for fine-tuning the model.
The code for generating the data.
The code for fine-tuning the model.
The code for recovering Alpaca-7B weights from our released weight diff.
Below The Fold

E2M is a Python library that can parse and convert various file types into Markdown format. By utilizing a parser-converter architecture, it supports the conversion of multiple file formats, including doc, docx, epub, html, htm, url, pdf, ppt, pptx, mp3, and m4a.
✨The ultimate goal of the E2M project is to provide high-quality data for Retrieval-Augmented Generation (RAG) and model training or fine-tuning.
Core Architecture of the Project:
Parser: Responsible for parsing various file types into text or image data.
Converter: Responsible for converting text or image data into Markdown format.
Generally, for any type of file, the parser is run first to extract internal data such as text and images. Then, the converter is used to transform this data into Markdown format.
Yazi (means "duck") is a terminal file manager written in Rust, based on non-blocking async I/O. It aims to provide an efficient, user-friendly, and customizable file management experience.
Teable uses a simple, spreadsheet-like interface to create powerful database applications.

A shell compiler that converts shell scripts into secure, portable and static binaries. Unlike other tools (ie. shc), Bunster does not just wrap your script within a binary. It literally compiles them to standalone shell-independent programs.
Under the hood, Bunster transpiles shell scripts into Go code. Then uses the Go Toolchain to compile the code to an executable.
Bunster aims to be compatible with bash as a starting move. Expecting that most bash scripts will just work with bunster. Additional shells will be supported as soon as we release v1.
ty is an extremely fast Python type checker and language server, written in Rust.