

Apple announces Apple Intelligence
Mozilla's llama files for RAG, LLama3 in Numpy!

Apple Intelligence Commentary
Apple is playing catchup not only in Generative AI, but overall in AI space. The features were not new or innovative, but rather what are available in Samsung and Google ecosystem for a while. From that perspective, I looked at the news to compare how behind Apple is comparing to industry rather than taking the features as they are. Also, the other thing that I noticed is that, these features are well announced more than 1 year before it becomes a reality.
Apple first used to do demos that they can roll out right away. This is also what we used to see especially in iPhone new software releases.
Then, they did product announcements for 3-6 months period in the sense that they announce new features and do a very small/beta rollout and then rollout to the global population 6 moths later.
Now, they are doing 3rd party integration announcements in a 1 year prior; which looks to be regressing over time. This optics looks to be very counter-intuitive for a company that can delivery very high quality hardware and products where their software announcements lag much behind than hardware announcements.
Another thing that was counter-intuitive to me is that Apple generally integrates end to end product experience for a given user. This is their “secret sauce” where though end to end integration, they can both create “moat” for themselves(lock-in for a user), but this also allows them to build better products as software can be optimized for hardware or vice versa. In ChatGPT announcement, this end to end experience/product development is also broken as the software/logic/model for Siri and LLM will be a 3rd party and it is not clear how this experience can play into this Apple’s strength. I am sure that Apple considers this as a stop-gap measure until their LLM capabilities are on par with industry, but given the announcement for 3rd party is a year in future, I thought they could have done built themselves if they can commit and dedicate this capability given that they already have Siri in production and possibly I assume that they have a know-how in the infrastructure and deployment; only ML capabilities would be missing in building this remaining capability.
Now, back to original programming:
Articles

Apple last week announced Apple Intelligence, under the hood mainly the features that will be powered through Generative AI models; mainly LLMs. On a high level, one can categorize these features text based and image/video based models, but more importantly, one thing that I thought it might be interesting to cover is the server based models and on-device models. As Apple has a big presence in the USA and rest of the world around the devices especially mobile devices like iPhone, iPad, they also have a big opportunity to actually deploy very large on-device models as well.

On-Device Language Model
The making on-device language model work is a hard engineering problem, packing a staggering 3 billion parameters into a compact form factor that can run entirely on the user's device without requiring server based deployments. This model is responsible for enabling a list of language-related features, including:
Writing Tools: The on-device model powers the Rewrite, Proofread, and Summarize features within apps like Pages, Notes, and Mail. It can intelligently rephrase text, suggest grammatical and stylistic improvements, and generate concise summaries of lengthy documents or email threads.
Smart Reply: In messaging apps like Mail and Messages, the on-device model provides intelligent reply suggestions, saving users time and effort when responding to communications.
Notification Management: By understanding the context and content of notifications, the model can prioritize and summarize important alerts, ensuring users stay informed without being overwhelmed.
Audio Transcription and Summarization: The model can transcribe and summarize audio recordings, making it easier to review and extract key information from meetings, lectures, or podcasts.
The on-device processing of this language model is a critical aspect of Apple Intelligence, as it ensures user data privacy and low-latency performance for these language tasks.

Server Language Model
While the on-device model is powerful, some language tasks require even more computational resources. For these scenarios, Apple has developed a larger language model that runs on dedicated Apple silicon servers. The server language model enables advanced capabilities such as:
Long-form Writing Assistance: The model can assist with generating longer, more complex pieces of writing, such as essays, reports, or creative works.
Context-Rich Query Handling: By leveraging its vast knowledge base and processing power, the server model can handle intricate queries that require significant context and reasoning.
Open-Ended Question Answering: Through integration with the powerful ChatGPT model, Apple Intelligence can provide detailed and nuanced responses to open-ended questions across a wide range of topics.
For multi-modal features, most of the features will be probably provided through the server based deployment and serving. From Apple, given their strong focus on user privacy, I am expecting a lot of innovations on device models, but I am also curious if they would want to use their latest/greatest M3 chips as well to build powerful models to power different LLM capabilities.

In the pursuit of building more intelligent and context-aware applications, the field of natural language processing has seen a surge in the development of retrieval-augmented generation (RAG) techniques.
RAG combines large language models with a retrieval system, enabling more informed and contextual responses. However, running RAG applications on local hardware has been a challenge due to the computational demands of generating text embeddings for large datasets. Mozilla wrote a blog post on this where llamafiles come into play, they offer a solution to enable efficient and scalable local RAG applications.
Embeddings play a crucial role in RAG applications, as they facilitate the retrieval of relevant information from a knowledge base to augment the language model's generation capabilities.Generating embeddings for large datasets can be computationally expensive, making it challenging to run RAG applications on local hardware with limited resources. Llamafiles address this challenge by providing optimized and compressed versions of state-of-the-art text embedding models that can be easily loaded and used on local machines. These optimized models are designed to strike a balance between performance and memory footprint, enabling efficient storage and utilization of high-quality embeddings on local hardware. By leveraging llamafiles, developers can overcome the computational barriers and bring the power of RAG applications to a wider range of devices and environments.
To ensure the selection of high-quality text embedding models for llamafiles, Mozilla relied on the Massive Text Embedding Benchmark (MTEB), a comprehensive evaluation suite specifically designed to assess the performance of text embedding models on tasks relevant to RAG applications. Rather than relying solely on the traditional average score metric, the authors took a more nuanced approach by filtering the MTEB leaderboard to include only RAG-relevant tasks and using a modified ranking metric called mean task rank (MTR). This approach addresses the issue of non-commensurate scores across different task types and provides a more robust ranking for RAG applications. By leveraging the MTEB benchmark and the MTR metric, the authors were able to identify and recommend the most suitable text embedding models for llamafiles, ensuring optimal performance in local RAG applications.
Based on the MTEB benchmark results, the article recommends three llamafile embedding models:
Salesforce/SFR-Embedding-Mistral: Considered the best overall model, achieving top performance on RAG-relevant tasks in the MTEB benchmark. It was fine-tuned on multiple datasets using multi-task learning, improving its generalization capabilities.
intfloat/e5-mistral-7b-instruct: Recommended for applications requiring a commercial-friendly license, this model was fine-tuned on synthetic data generated by another large language model, resulting in strong performance.
mixedbread-ai/mxbai-embed-large-v1: The recommended small model, suitable for memory-constrained environments. It was trained on a large curated dataset using contrastive learning and AngIE loss, achieving impressive performance despite its compact size.

The selection of these models was based on factors such as model size, memory constraints, document length, and the size of the generation model used in the RAG application. Additionally, various optimization techniques, including multi-task learning, fine-tuning on synthetic data, and contrastive learning with AngIE loss, were employed to enhance the performance of these models.
To facilitate the adoption and integration of llamafiles into RAG applications, they used the embeddings with popular RAG application development frameworks like LlamaIndex and LangChain. This integration allows incorporating the optimized embedding models provided by llamafiles into their applications, streamlining the development process. The article includes a minimal example of a local RAG app using llamafiles, demonstrating the ease of integration and providing developers with a starting point for building their own applications.
Missing Papers wrote an article to provide an intuitive understanding of the Llama 3 model structure by implementing it using only NumPy The implementation is based on the stories15M model trained by Andrej Karpathy, which follows the Llama 2 architecture but does not incorporate the Grouped Query Attention (GQA) technique used in Llama 3.

The Llama 3 model structure is identical to the 42dot LLM architecture, consisting of several key components:
Rotary Position Embedding (RoPE): This technique is used for position encoding, combining aspects of both absolute and relative positional information. The implementation involves precomputing cosine and sine values, which are later applied to the query (Q) and key (K) vectors.
RMSNorm: Llama 3 employs RMSNorm for normalization, which scales activation values based on the Root Mean Square (RMS) of the activations. This approach ensures consistent scaling regardless of batch size or layer.
Query, Key, Value (QKV) Calculation: Unlike the GPT model, which calculates QKV by multiplying a single weight matrix, Llama 3 has separate weight matrices for Q, K, and V. The implementation reshapes these vectors to separate them by multi-head attention.
RoPE Application: After calculating QKV, the precomputed RoPE values are applied to Q and K, enabling the model to capture both absolute and relative positional information.
Key-Value (KV) Cache: Since the model follows a masked attention mechanism, the K and V vectors can be cached, reducing computational overhead during generation.
Grouped Query Attention (GQA): Although not applied in the provided implementation due to the use of the stories15M model, the article includes code for GQA, which was introduced in Llama 2 to improve performance and memory efficiency compared to traditional multi-head attention.
Scaled Dot-Product Attention: The attention mechanism follows the standard scaled dot-product attention formula, with separate calculations for each multi-head.
Feed Forward Network (FFN): Llama 3 employs a unique FFN architecture, using three linear layers without bias terms. The implementation includes the SwiGLU activation function, which combines the Swish and GLU (Gated Linear Unit) functions.
Linear Output Layer: After passing through the transformer blocks, the final output is computed using a linear layer, producing logits for the vocabulary.

The author also provides a simplified implementation of the generation process, focusing on greedy decoding. The generation process is divided into two phases:
Prefill Phase: In this phase, all input tokens are processed, and the model generates the initial output.
Decode Phase: During this phase, the model generates one token at a time, leveraging the KV cache to reduce computational overhead.
The implementation omits sampling techniques like top-k and top-p for simplicity.
All of the code is available throughout the article and full source code is also available in here.
Libraries

Inspectus is a versatile visualization tool for large language models. It runs smoothly in Jupyter notebooks via an easy-to-use Python API. Inspectus provides multiple views, offering diverse insights into language model behaviors.
Components
Attention Matrix: Visualizes the attention scores between tokens, highlighting how each token focuses on others during processing.
Query Token Heatmap: Shows the sum of attention scores between each query and selected key tokens
Key Token Heatmap: Shows the sum of attention scores between each key and selected query tokens
Dimension Heatmap: Shows the sum of attention scores for each item in dimensions (Layers and Heads) normalized over the dimension.
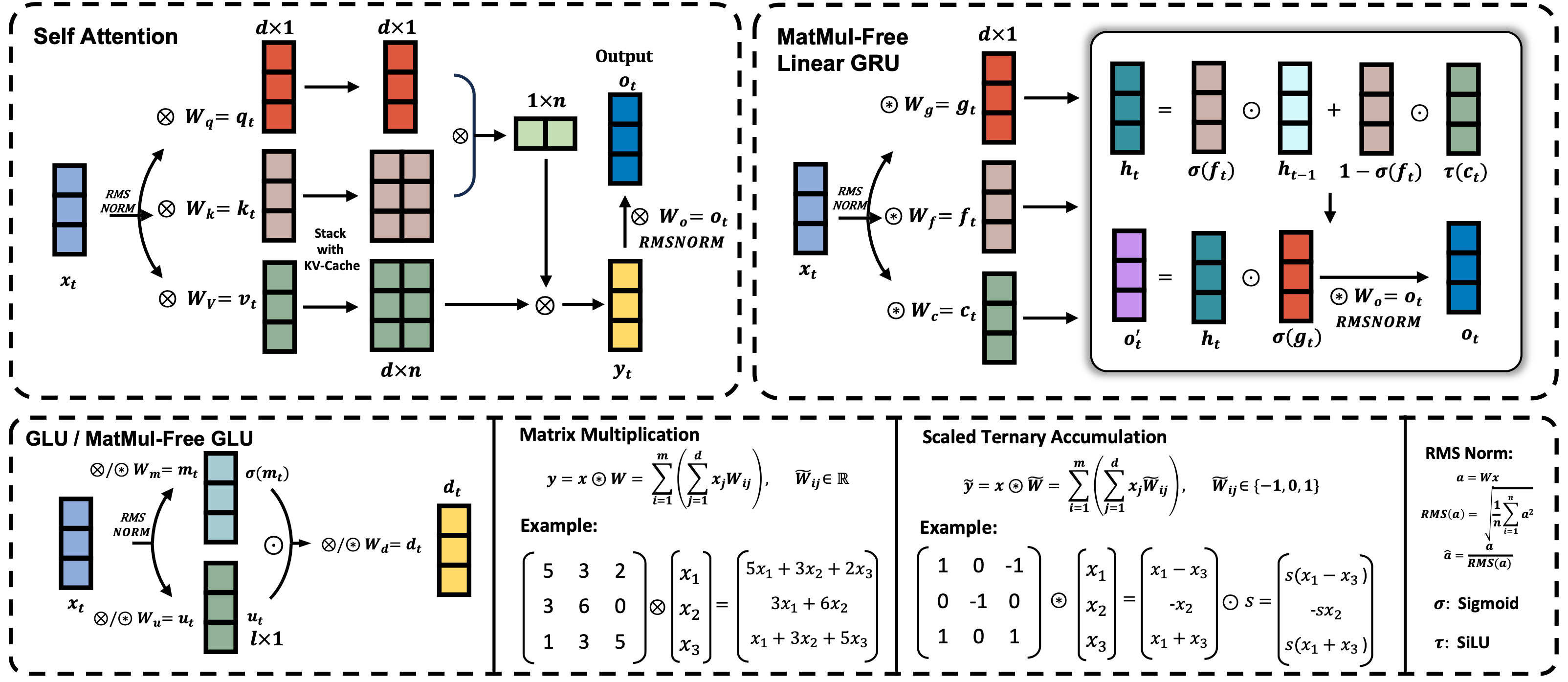
MatMul-Free LM is a language model architecture that eliminates the need for Matrix Multiplication (MatMul) operations. This repository provides an implementation of MatMul-Free LM that is compatible with the 🤗 Transformers library.

They evaluate how the scaling law fits to the 370M, 1.3B and 2.7B parameter models in both Transformer++ and our model. For a fair comparison, each operation is treated identically, though our model uses more efficient ternary weights in some layers. Interestingly, the scaling projection for our model exhibits a steeper descent compared to Transformer++, suggesting our architecture is more efficient in leveraging additional compute to improve performance.

xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models.
NNX is a JAX-based neural network library that focuses on providing the best development experience to make building and experimenting with neural networks as easy and intuitive as possible. It is now part of Flax as well.
Pythonic: Modules are standard Python classes, promoting ease of use and a more familiar development experience.
Easy-to-use: NNX provides a set of transforms that take care of state management, allowing users to focus on building their models and training loops.
Expressive: NNX allows fine-grained over the Module state with lifted transforms, enabling users to define complex architectures.
Compatible: NNX allows functionalizing Module state, making it possible to directly use JAX transformations when needed.
Inspired by minGPT/nanoGPT and flax/examples, Nanodo provides a minimal implementation of a Transformer decoder-only language model in Jax.
The purpose is to be maximally hackable, forkable, and readable for researchers, to enable highly exploratory research. Magic is great for products, but it is harmful in many cases for research and so we minimize abstraction as a design goal.
🐶 MLX Bark
MLX Bark is a port of Suno's Bark model in Apple's ML Framework, MLX. Bark is a transformer based text-to-audio model that can generate speech and miscellaneous audio i.e. background noise / music.

Llamazing is a simple Web / UI / App / Frontend to Ollama.
Things I Enjoyed(TIE)

Victor Powell published a nice, interactive visualization for a perceptron modeland code for this visualization is here.

Introduction to ML is a good introduction to neural networks and core concepts in machine learning.

Epoch AI has a trends page that allows you to see the various trends in a single page(compute, data, hardware, algorithms, investment, etc). It is not updated very frequently, but it is good to keep an eye on it once a month or once a quarter.

Integrating GPT into Apple products is quite good. However, it lacks particularly groundbreaking innovations, mainly addressing some existing issues.