

Airbnb's Search Ranking Approach
Netflix's Long Term Reward Strategy

Airbnb's engineering team discusses the challenges and solutions in adapting search ranking for map-based interfaces. This post is very interesting as the ranking approach, algorithm as well as optimization function has to be rethought all the way to how user actually interacts with the application itself. Also, as the user interacts with the items not necessarily a pre-determined and deterministic order, this also requires thinking about position bias and other types of considerations that might be obvious in the list ranking(as the application can enforce a particular order for the items.
TLDR:
Map interfaces require rethinking traditional ranking assumptions
User attention on maps is more complex and requires multi-faceted modeling
Balancing high-probability listings with good spatial coverage is crucial
Tiered visual representation can effectively guide user attention to find the optimal listing for a given user
Continuous iteration and A/B testing are essential for optimizing map ranking
Main differences between a simple list ranking and map ranking boils down to the attention, but there are many more dimensions which I will list in below:
User Attention:
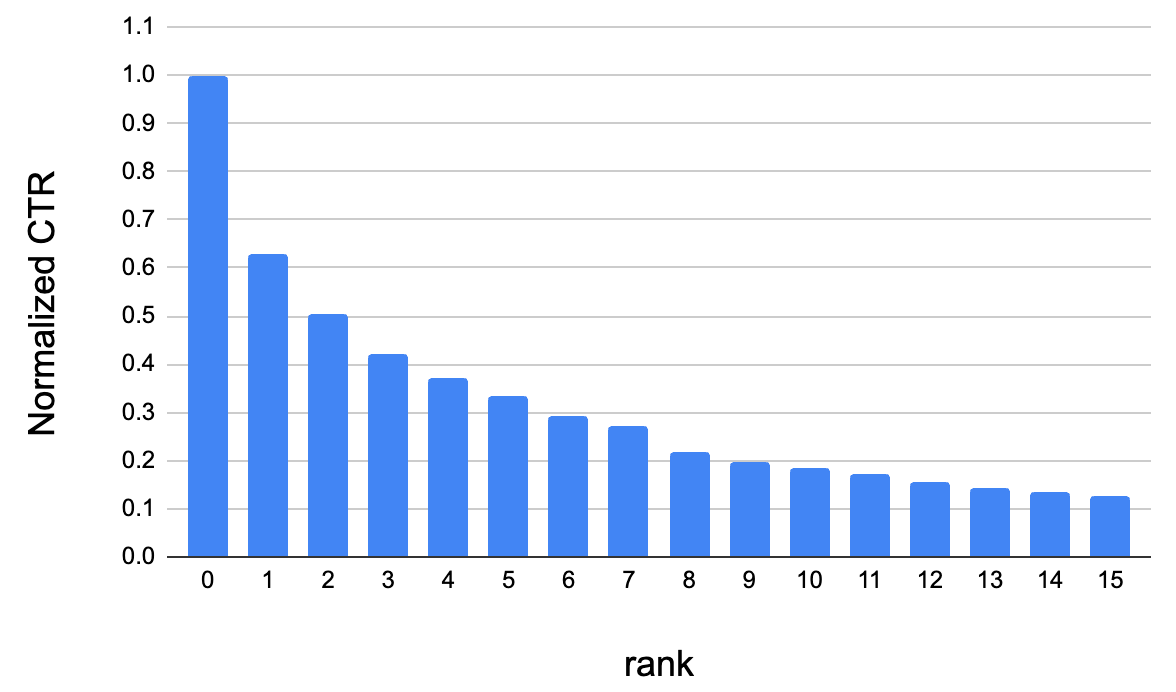
List Ranking
User attention decays from top to bottom
Click-through rates (CTR) decrease as rank position increases
Ranking strategy: Sort listings by booking probabilities
Map Ranking
User attention is scattered across the map
No clear decay of attention based on position
Traditional ranking strategy of sorting by booking probabilities is not applicable

Adapting Ranking for Maps
Uniform User Attention Model
Airbnb tested a hypothesis of uniform user attention across map pins:
Introduced a parameter α to control the ratio of highest to lowest booking probabilities for displayed pins
Restricted the range of booking probabilities for map pins
Results:
Reduced average impressions and clicks to discovery
Significant improvement in bookings and quality of bookings (5-star ratings)
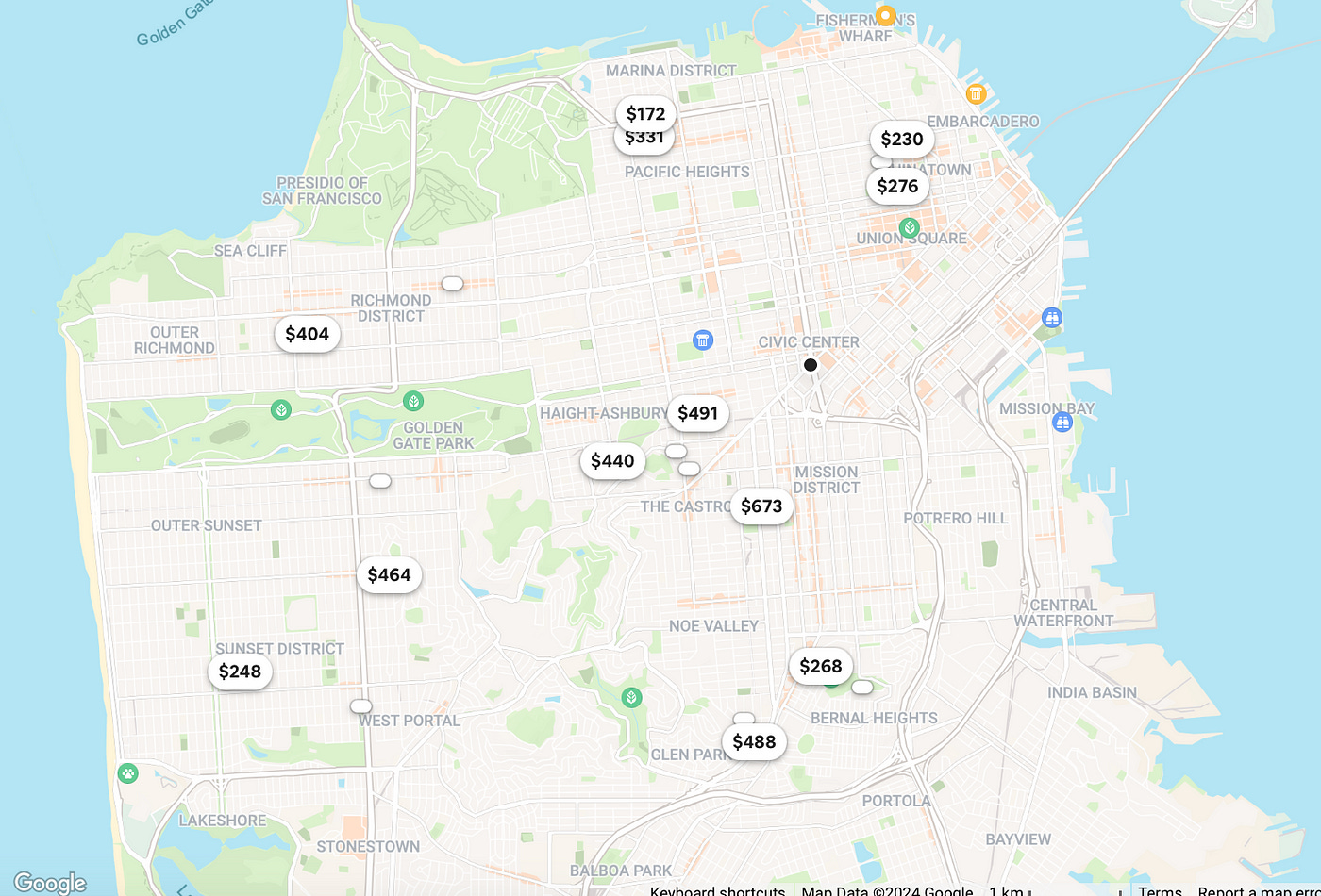
Tiered User Attention Model
To further refine the ranking approach, Airbnb implemented a two-tier system:
Regular oval pins with price: Highest booking probabilities
Mini-pins without price: Lower booking probabilities
Observations:
Mini-pins had 8x lower CTR than regular pins
Particularly useful for desktop searches with fixed number of results
Results:
Improved uncancelled bookings
Reduced map moves, indicating less user effort
Discounted User Attention Model
The final iteration involved a more sophisticated understanding of user attention distribution:
Analyzed CTR of map pins across different coordinates
Developed an algorithm to re-center the map based on listings with highest booking probabilities
Results:
0.27% improvement in uncancelled bookings
1.5% reduction in map moves

Other Differences
Ranking Factors
List Ranking: Primarily based on booking probabilities
Map Ranking: Considers booking probabilities, but also incorporates spatial distribution and user attention patterns
Result Presentation
List Ranking: Sequential order
Map Ranking: Scattered pins with varying visual prominence
User Interaction
List Ranking: Scrolling through a linear list
Map Ranking: Exploring a two-dimensional space, zooming, and panning
Optimization Goals
List Ranking: Maximize visibility of high-probability bookings at the top
Map Ranking: Balance between showing high-probability bookings and providing good coverage of the area
Algorithmic Approaches
List Ranking: Straightforward sorting by booking probability
Map Ranking: Complex algorithms considering spatial distribution, re-centering, and tiered presentation
Scalability
List Ranking: Easily scalable to large result sets
Map Ranking: Challenges with representing a full range of available listings
Personalization
List Ranking: Can be personalized based on user preferences
Map Ranking: Personalization needs to consider both user preferences and spatial context
Visual Hierarchy
List Ranking: Achieved through position in the list
Map Ranking: Achieved through pin size, color, and placement
User Cognitive Load
List Ranking: Sequential processing of information
Map Ranking: Parallel processing of spatial information
Adaptation to Screen Size
List Ranking: Relatively consistent across devices
Map Ranking: Significant differences between mobile and desktop interfaces
Handling of Low-Probability Results
List Ranking: Typically pushed to later pages
Map Ranking: Represented as mini-pins or potentially omitted
Impact of Result Density
List Ranking: Consistent presentation regardless of result density
Map Ranking: Challenges in areas with high listing density
User Control
List Ranking: Limited to scrolling and page navigation
Map Ranking: Users can actively explore different areas and zoom levels
Performance Metrics
List Ranking: Focus on position-based CTR and conversion rates
Map Ranking: Incorporates metrics like map moves and pin interaction rates
After last week’s post, there were a lot of positive feedback on the Netflix’s approach of building recommender systems and here is an excellent post much more detailed on the Long term rewards and how Netflix thinks about long term reward.
They focus on long-term satisfaction due to the following reasons:
User Experience: Providing members with content they genuinely enjoy over time enhances their overall experience with the platform.
Member Retention: Satisfied members are more likely to continue their subscriptions, reducing churn.
Business Performance: Improved long-term satisfaction can lead to increased viewer activity and, ultimately, better financial outcomes for Netflix.
Traditional recommender systems often optimize for short-term metrics like clicks or engagement, which may not fully capture long-term satisfaction. Netflix's approach seeks to bridge this gap by developing more sophisticated recommendation strategies.
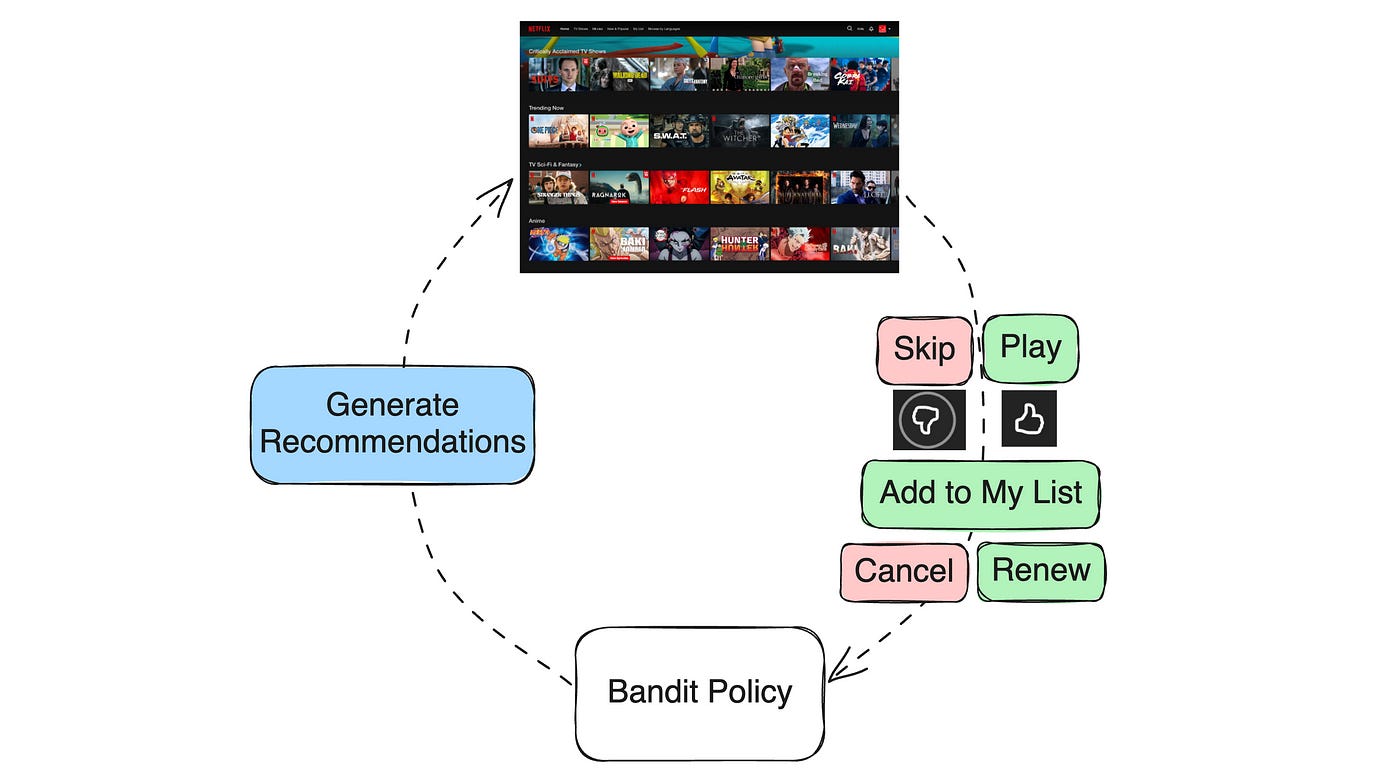
Recommendations as Contextual Bandit
Netflix frames its recommendation problem as a contextual bandit(CB), a type of reinforcement learning algorithm where they define the following concepts in the CB:
Context: When a member visits the platform, it creates a context for the system.
Action: The system selects an action by deciding which recommendations to show.
Feedback: The member provides various types of feedback, both immediate and delayed.
This approach allows Netflix to define reward functions that reflect the quality of recommendations based on user feedback signals. The system then trains a contextual bandit policy on historical data to maximize the expected reward.
Challenges with Retention as a Direct Reward
Netflix identifies several drawbacks to using it directly as a reward:
Noise: Retention can be influenced by external factors unrelated to the service quality.
Low Sensitivity: It only captures extreme cases where members are on the verge of canceling.
Attribution Difficulty: Cancellations might result from a series of poor recommendations rather than a single event.
Slow Measurement: Retention data is only available on a monthly basis per account.
These challenges make optimizing directly for retention impractical, leading Netflix to explore alternative approaches.

Proxy Rewards
To address the limitations of using retention directly, Netflix employs proxy reward functions. These functions aim to align closely with long-term member satisfaction while being sensitive to individual recommendations
The proxy reward is defined as:

Where user interactions can include various actions such as playing, completing, or rating content.
Click-Through Rate (CTR)
CTR serves as a simple baseline proxy reward, where:

While CTR is a common and strong baseline, Netflix recognizes that over-optimizing for it can lead to promoting "clickbaity" items that may harm long-term satisfaction.
Beyond CTR
To better align with long-term satisfaction, Netflix considers a wide range of user actions and their implications:
Fast season completion: Completing a TV show season quickly is seen as a strong positive signal.
Negative feedback after completion: Finishing a show over weeks but giving it a thumbs-down indicates low satisfaction despite significant time investment.
Brief engagements: Short viewing sessions are ambiguous and require careful interpretation.
Genre discovery: Engaging with new genres after recommendations is viewed very positively.

Reward Engineering
Netflix employs an iterative process called reward engineering to refine their proxy reward functions. This process involves four stages:
Hypothesis formation
Defining a new proxy reward
Training a new bandit policy
A/B testing
This approach allows Netflix to continuously improve their reward functions based on observed data and member behavior.
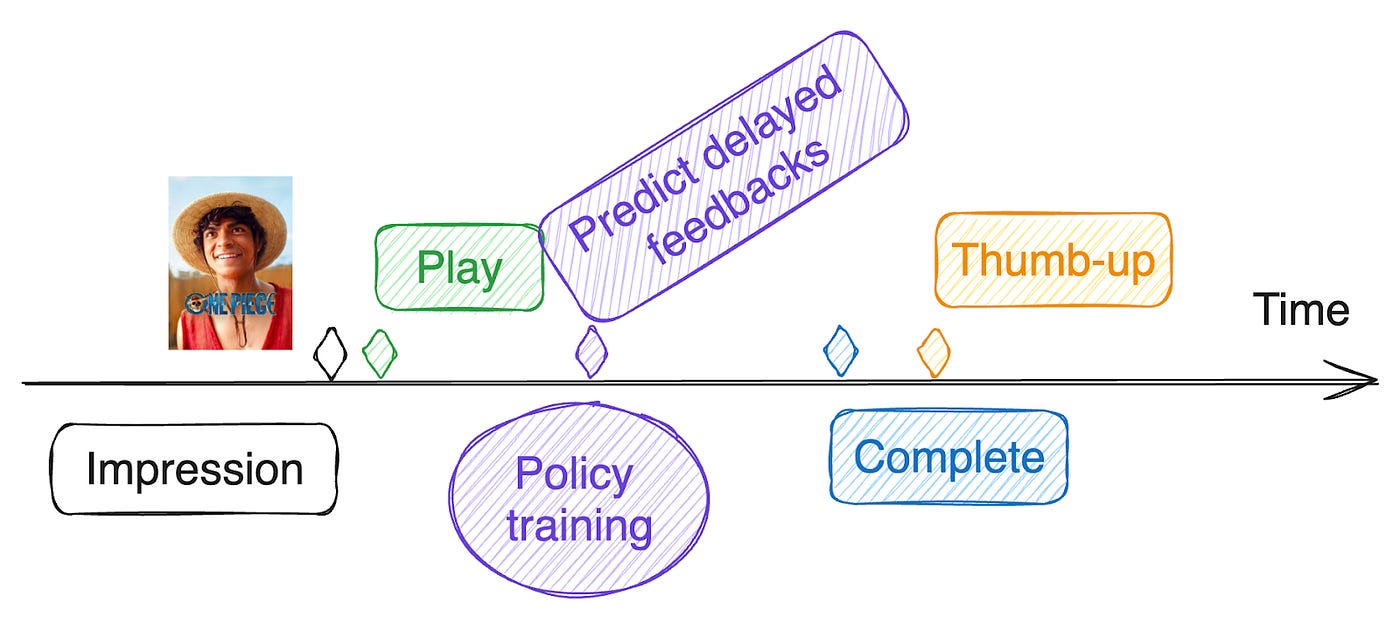
Dealing with Delayed Feedback
A significant challenge in Netflix's recommendation system is handling delayed or missing feedback. Users may take weeks to complete a show or may never provide explicit feedback like ratings. To address this, Netflix has developed a sophisticated approach:
Predict Missing Feedback: Instead of waiting for delayed feedback, Netflix predicts it using already observed data and other relevant information up to the training time.
Proxy Reward Calculation: The proxy reward is calculated using both observed and predicted feedback for each training example.
Bandit Policy Update: These training examples are then used to update the bandit policy.
This approach allows Netflix to update their recommendation policy quickly while still incorporating long-term feedback signals.
There is also a paper that goes into much more detail about the reward building process as well as technical implementation details.
Libraries

Byte Latent Transformer architecture (BLTs), a new byte-level LLM architecture that for the first time, matches tokenization-based LLM performance at scale, with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented dynamically based on the entropy of the next byte, allocating more compute and model capacity where there is more data complexity. The BLT architecture includes new attention mechanisms to maximize the information flow between byte and patch hidden representations and a new type of byte-sequence memory.

Harbor is a containerized LLM toolkit that allows you to run LLMs and additional services. It consists of a CLI and a companion App that allows you to manage and run AI services with ease. Effortlessly run LLM backends, APIs, frontends, and services with one command.
DolphinScheduler is the modern data orchestration platform. Agile to create high performance workflow with low-code. It is also provided powerful user interface, dedicated to solving complex task dependencies in the data pipeline and providing various types of jobs available out of the box
The key features for DolphinScheduler are as follows:
Easy to deploy, provide four ways to deploy which including Standalone, Cluster, Docker and Kubernetes.
Easy to use, workflow can be created and managed by four ways, which including Web UI, Python SDK and Open API
Highly reliable and high availability, decentralized architecture with multi-master and multi-worker, native supports horizontal scaling.
High performance, its performance is N times faster than other orchestration platform and it can support tens of millions of tasks per day
Cloud Native, DolphinScheduler supports orchestrating multi-cloud/data center workflow, and supports custom task type
Versioning both workflow and workflow instance(including tasks)
Various state control of workflow and task, support pause/stop/recover them in any time
Multi-tenancy support
Others like backfill support(Web UI native), permission control including project and data source

flow_matching is a PyTorch library for Flow Matching algorithms, featuring continuous and discrete implementations. It includes examples for both text and image modalities. This repository is part of Flow Matching Guide and Codebase.

Polars is a DataFrame interface on top of an OLAP Query Engine implemented in Rust using Apache Arrow Columnar Format as the memory model.
Lazy | eager execution
Multi-threaded
SIMD
Query optimization
Powerful expression API
Hybrid Streaming (larger-than-RAM datasets)
Rust | Python | NodeJS | R | ...